前言 前面一小节我们简单深入的梳理了垃圾收集器,梳理理解了各个垃圾收集器的原理和回收流程。其中主要的垃圾收集器可以分为“经典垃圾收集器”和“低延迟垃圾收集器”,其中经典垃圾收集器是以Parallel、CMS、G1为首在生产环境经过千万次历练的垃圾收集器。低延迟垃圾收集器们则是最新还处于实验状态的 shenandoah 和 ZGC,这一代的设计目标是在超大堆下依旧能能实现高吞吐低延迟的垃圾收集。但是就目前为止,我们在生产环境使用的依旧是经典垃圾收集器,因此在GC环境,我们依旧要对GC进行调优以充分利用物理机的性能。GC调优这个词我们听过很多次,但是真正操作起来可能会像不知所措无从下手。但是朋友不要害怕,有了前面的基础铺垫再加上一些监控指标,经过这一小节,你一定会对GC调优有个全面的认识。这一小节我们会先从GC调优分析开始,介绍调优的基本流程、GC的一些限制,随后我们进行一段调优的示例,在示例中我们如何进行日志分析与GC调优。最后我们会梳理一个简单的产生垃圾的程序,并分析在不同的垃圾收集器下的GC日志分析调优。
日志解读 上一节我们介绍了各种垃圾收集器。如果定位GC问题和GC调优我们离不开对GC日志的分析。在这个部分我们将分析这些GC的日志,来分GC日志中隐藏的GC垃圾收集信息。
Serial GC 日志解读 我们为了能够打开GC日志记录并指定垃圾收集器为Serial,我们使用下面的JVM启动参数:
1 2 -XX:+UseSerialGC -Xms512m -Xmx512m -Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
使用上面的JVM启动参数,我们可以得到如下的日志输出(p.s. 已经手工折叠部分日志)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 Java HotSpot ( TM ) 64 - Bit Server VM ( 25.231 - b11 ) for bsd - amd64 JRE ( 1.8 .0 _ 231 - b11 ) , built on Oct 5 2019 03 : 15 : 25 by "java_re" with gcc 4.2 .1 ( Based on Apple Inc . build 5658 ) ( LLVM build 2336.11 .00 ) Memory : 4 k page , physical 16777216 k ( 794016 k free ) / proc / meminfo : CommandLine flags : - XX : InitialHeapSize = 536870912 - XX : MaxHeapSize = 536870912 - XX :+ PrintGC - XX :+ PrintGCDateStamps - XX :+ PrintGCDetails - XX :+ PrintGCTimeStamps - XX :+ UseCompressedClassPointers - XX :+ UseCompressedOops - XX :+ UseSerialGC 2021 - 07 - 11 T18 : 30 : 13.329 - 0800 : 0.177 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 13.329 - 0800 : 0.177 : [ DefNew : 139776 K -> 17472 K ( 157248 K ) , 0.0219962 secs ] 139776 K -> 45575 K ( 506816 K ) , 0.0221202 secs ] [ Times : user = 0.01 sys = 0.01 , real = 0.03 secs ] 2021 - 07 - 11 T18 : 30 : 13.369 - 0800 : 0.217 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 13.369 - 0800 : 0.217 : [ DefNew : 157248 K -> 17471 K ( 157248 K ) , 0.0271936 secs ] 185351 K -> 89018 K ( 506816 K ) , 0.0272786 secs ] [ Times : user = 0.01 sys = 0.01 , real = 0.03 secs ] 2021 - 07 - 11 T18 : 30 : 13.412 - 0800 : 0.260 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 13.412 - 0800 : 0.260 : [ DefNew : 157247 K -> 17471 K ( 157248 K ) , 0.0224308 secs ] 228794 K -> 134099 K ( 506816 K ) , 0.0225212 secs ] [ Times : user = 0.01 sys = 0.01 , real = 0.02 secs ] ...... 2021 - 07 - 11 T18 : 30 : 13.931 - 0800 : 0.779 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 13.931 - 0800 : 0.779 : [ DefNew : 157243 K -> 157243 K ( 157248 K ) , 0.0000170 secs ] 2021 - 07 - 11 T18 : 30 : 13.931 - 0800 : 0.779 : [ Tenured : 332621 K -> 341869 K ( 349568 K ) , 0.0488050 secs ] 489864 K -> 341869 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0489122 secs ] [ Times : user = 0.04 sys = 0.00 , real = 0.05 secs ] 2021 - 07 - 11 T18 : 30 : 13.997 - 0800 : 0.845 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 13.997 - 0800 : 0.845 : [ DefNew : 139776 K -> 139776 K ( 157248 K ) , 0.0000171 secs ] 2021 - 07 - 11 T18 : 30 : 13.997 - 0800 : 0.845 : [ Tenured : 341869 K -> 340659 K ( 349568 K ) , 0.0437236 secs ] 481645 K -> 340659 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0438227 secs ] [ Times : user = 0.04 sys = 0.00 , real = 0.05 secs ] 2021 - 07 - 11 T18 : 30 : 14.058 - 0800 : 0.906 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 14.058 - 0800 : 0.906 : [ DefNew : 139776 K -> 139776 K ( 157248 K ) , 0.0000175 secs ] 2021 - 07 - 11 T18 : 30 : 14.058 - 0800 : 0.906 : [ Tenured : 340659 K -> 342260 K ( 349568 K ) , 0.0457178 secs ] 480435 K -> 342260 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0458305 secs ] [ Times : user = 0.04 sys = 0.00 , real = 0.05 secs ] 2021 - 07 - 11 T18 : 30 : 14.122 - 0800 : 0.970 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 14.122 - 0800 : 0.970 : [ DefNew : 139776 K -> 139776 K ( 157248 K ) , 0.0000197 secs ] 2021 - 07 - 11 T18 : 30 : 14.122 - 0800 : 0.970 : [ Tenured : 342260 K -> 332184 K ( 349568 K ) , 0.0497748 secs ] 482036 K -> 332184 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0498987 secs ] [ Times : user = 0.05 sys = 0.00 , real = 0.05 secs ] 2021 - 07 - 11 T18 : 30 : 14.190 - 0800 : 1.038 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 14.190 - 0800 : 1.038 : [ DefNew : 139776 K -> 139776 K ( 157248 K ) , 0.0000187 secs ] 2021 - 07 - 11 T18 : 30 : 14.190 - 0800 : 1.038 : [ Tenured : 332184 K -> 349062 K ( 349568 K ) , 0.0294194 secs ] 471960 K -> 353796 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0295288 secs ] [ Times : user = 0.03 sys = 0.01 , real = 0.03 secs ] 2021 - 07 - 11 T18 : 30 : 14.241 - 0800 : 1.089 : [ Full GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 14.241 - 0800 : 1.089 : [ Tenured : 349062 K -> 349274 K ( 349568 K ) , 0.0397096 secs ] 506055 K -> 351244 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0398051 secs ] [ Times : user = 0.04 sys = 0.00 , real = 0.04 secs ] Heap def new generation total 157248 K , used 8337 K [ 0 x00000007a0000000 , 0 x00000007aaaa0000 , 0 x00000007aaaa0000 ) eden space 139776 K , 5 % used [ 0 x00000007a0000000 , 0 x00000007a08244f0 , 0 x00000007a8880000 ) from space 17472 K , 0 % used [ 0 x00000007a8880000 , 0 x00000007a8880000 , 0 x00000007a9990000 ) to space 17472 K , 0 % used [ 0 x00000007a9990000 , 0 x00000007a9990000 , 0 x00000007aaaa0000 ) tenured generation total 349568 K , used 349274 K [ 0 x00000007aaaa0000 , 0 x00000007c0000000 , 0 x00000007c0000000 ) the space 349568 K , 99 % used [ 0 x00000007aaaa0000 , 0 x00000007bffb6998 , 0 x00000007bffb6a00 , 0 x00000007c0000000 ) Metaspace used 2571 K , capacity 4486 K , committed 4864 K , reserved 1056768 K class space used 276 K , capacity 386 K , committed 512 K , reserved 1048576 K
其中我们不难看出,输出的日志信息一眼看上去简单可以分为三大块,第一个部分是JVM版本信息和一些执行机器的内存情况 ,第二个部分日志块是JVM的执行参数和日志信息 。最后一个块是程序结束时堆空间和元数据区的内存使用情况 。来我们先看年轻代的GC日志,下面是我们GC日志中的第二次GC事件。
MinorGC 日志分析 1 2 3 4 2021 -07 -11 T18 :30 :13 .369 -0800 : 0 .217 : [GC (Allocation Failure) 2021-07-11T18:30:13.369-0800: 0.217: [DefNew: 157248K->17471K(157248K), 0.0271936 secs] 185351K->89018K(506816K), 0.0272786 secs] [Times: user=0.01 sys=0.01, real=0.03 secs]
从上面的日志信息中可以解读出如下的信息:
2021-07-11T18:30:13.369-0800 GC事件开始的时间点,其中-0800表示当前时区为东八区,这只是一个标识,方便我们直观判断GC发生的时间点。后面的0.217 是GC事件相较于JVM启动事件的间隔,单位是秒。GC用来区分 MinorGC 还是 FullGC 的标志。GC表明这是一次小型GC(Minor GC),即年轻代GC。Allocation Failure 表示触发GC的原因。本次GC事件,是由于对象分配失败,即年轻代中没有空间用来存放新生成的对象引起的。DefNew 表示垃圾收集器的名称。这个名字表示:年轻代使用单线程、标记-复制、STW垃圾收集器。157248K->17471K表示在垃圾收集之前和只之后的年轻代使用量。(157248K)表示年轻代的总空间大小。进一步分析可知:GC之后年轻代使用率为11%。185351K->89018K(506816K)表示在垃圾收集之前和之后整个堆内存的使用情况。(506816K)则表示堆内存可以用空间总大小。进一步分析可知:GC之后堆内存使用量为17.5%0.0272786 secs GC事件持续的时间,以秒为单位。[Times: user=0.01 sys=0.01, real=0.03 secs] 此次GC时间的持续时间,通过三个部分衡量:user部分表示所有GC线程消耗的CPU时间;sys部分表示系统调用和系统等待事件消耗的时间。real则表示应用程序暂停的时间。因为串行垃圾收集器(Serial Garbage Collector)只使用单个线程,所以这里 real ~= user + system, 0.03秒也就是30毫秒。
就经验而谈,这个暂停时间对大部分系统来说可以接受,但是对于某些延迟敏感的系统来说就是大问题了,就比如你打网络游戏,这30ms的暂停造成的延迟就会让你很难接受。
通过这样的解读我们可以分析JVM在GC时间中的内存使用以及变化情况。在此次垃圾收集之前,对内存总的使用量为185351K,而年轻代的空间使用量为157248K,不难算出老年代已经占用了28103K。当然这些数字中还蕴含更重要的信息:GC前后对比年轻代使用量从157248K->17471K减少了139777K,而总堆空间大小185351K->89018K只下降了96333K的内存空间。其中有43444K(139777K-96333K) 对象从年轻代提升到老年代。
通过这么分析下来,不难看出,我们关注的主要两个数据:GC暂停时间 ,以及GC之后的内存使用量/使用率 。
FullGC 日志分析 前面分析完成MinorGC的日志,我们对GC日志的格式也大致有一个概念了,我们接下来一起看看分析FullGC的日志。
1 2 3 4 5 6 7 8 2021 - 07 - 11 T18 : 30 : 13.840 - 0800 : 0.688 : [ GC ( Allocation Failure ) 2021 - 07 - 11 T18 : 30 : 13.840 - 0800 : 0.688 : [ DefNew : 139776 K -> 139776 K ( 157248 K ) , 0.0000196 secs ] 2021 - 07 - 11 T18 : 30 : 13.840 - 0800 : 0.688 : [ Tenured : 309538 K -> 298877 K ( 349568 K ) , 0.0407769 secs ] 449314 K -> 298877 K ( 506816 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0409461 secs ] [ Times : user = 0.04 sys = 0.00 , real = 0.04 secs ]
从上面的日志信息可以解读出这些信息:
2021-07-11T18:30:13.840-0800 GC事件的开始时间。[DefNew: 139776K->139776K(157248K), 0.0000196 secs] 前面已经解读过这段日志了,因为内存分配失败,发生了一次年轻代GC。此次GC同样使用了 DefNew 收集器。注意:此次垃圾收集器消耗了0.0000196 secs,并且年轻代空间并没有减少,基本上可以确认这次GC事件没怎么处理年轻代。Tenured 用于清理老年代空间的垃圾收集器名称。Tenured表明使用的是单线程的STW垃圾收集器,使用的算法标记-清理-整理(mark-sweep-compact)。309538K->298877K表示GC前后的堆内存的使用情况,以及老年代的大小。0.0407769 secs 是清理老年代所花的时间。449314K->298877K(506816K) 在GC前后整个堆内存部分的使用情况,以及可用堆空间大小。[Metaspace: 2565K->2565K(1056768K)], 0.0409461 secs] Metaspace 空间的变化情况。可以看出,此次GC过程中 Metaspace 也没有变化。[Times: user=0.04 sys=0.00, real=0.04 secs] GC事件的持续事件,分别为user,sys,real三个部分。因为串行垃圾收集器只使用单个线程,所以user + sys = real。这40ms 的暂停挺尸,比前面年轻代的暂停增大了不少,这个时间和什么有关系呢?GC时间,与GC后存活的对象总数量关系最大。
进一步分析这些数据,GC之后老年代的使用率为:298877K/349568K~=85.5%,这个比例已经很大了,这次老年代GC仅仅只回收了10661K,老年代触发FullGC但是老年代仅发生少量对象的回收,这个问题很大。同时我们发现和年轻代GC相比,比较明显的是这次GC事件还清理了老年代和Metaspace。
FullGC, 我们主要关注GC之后内存使用量是否下降,其次关注暂停时间。简单估算,GC后老年代使用量约为350MB,GC耗时40ms左右,如果我们把内存扩大10倍,GC后的老年代也扩大10倍,那么耗时将会达到400ms甚至更高,就会明显影响到系统的吞吐了。这也就是我们说串行性能弱的原因。服务端一般不会使用Serial GC。
Parallel GC 日志解读 并行的垃圾收集器对年轻代使用标记-复制(mark-copy)算法,对老年代使用标记-清除-整理(mark-sweep-compact)算法。年轻代和老年代的垃圾回收时都会触发STW事件,暂停所有的应用线程,再执行垃圾收集,在执行标记和复制/整理阶段时都使用多个线程。因此得名”Parallel”。通过多个GC线程并行执行的方式,能使JVM在多CPU平台上的GC时间大幅减少。通过命令行参数-XX:ParallelGCThread=N可以指定GC线程的数量,其默认是CPU内核数量。 下面三组命令是等价的都可以用来指定 ParallelGC
1 2 3 -XX:+UseParallelGC -XX:+UseParallelOldGC -XX:+UseParallelGC -XX:+UseParallelOldGC
我们使用下面的命令启动JVM,指定ParallelGC并指定输出gc日志。
1 2 -XX:+UseParallelGC -Xmx512m -Xms512m -Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
行垃圾收集器会适用于多核服务器,其主要目标是增加系统吞吐量(也就是降低GC总体消耗的时间)。为了达成这个目标,会尽量使用尽可能多的CPU资源:
在GC事件执行期间,所有CPU内核都在并行地清理垃圾,所以暂停时间相对来说更短。 在两次GC事件中间的间隙期,不会启动GC线程,所以这段事件内不会消耗任何系统资源。
另一方面,因为并行GC的所有阶段都是不能中断,所以并行GC很可能会出现长时间的卡顿。因为GC期间应用线程是被暂停的。如果单次暂停时间比较长对延迟要求很高,应该选择其他的垃圾收集器。下面是一段并行GC的日志。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 Java HotSpot ( TM ) 64 - Bit Server VM ( 25.231 - b11 ) for bsd - amd64 JRE ( 1.8 .0 _ 231 - b11 ) , built on Oct 5 2019 03 : 15 : 25 by "java_re" with gcc 4.2 .1 ( Based on Apple Inc . build 5658 ) ( LLVM build 2336.11 .00 ) Memory : 4 k page , physical 16777216 k ( 589368 k free ) / proc / meminfo : CommandLine flags : - XX : InitialHeapSize = 536870912 - XX : MaxHeapSize = 536870912 - XX :+ PrintGC - XX :+ PrintGCDateStamps - XX :+ PrintGCDetails - XX :+ PrintGCTimeStamps - XX :+ UseCompressedClassPointers - XX :+ UseCompressedOops - XX :+ UseParallelGC 2021 - 07 - 14 T00 : 42 : 11.646 - 0800 : 0.126 : [ GC ( Allocation Failure ) [ PSYoungGen : 131584 K -> 21502 K ( 153088 K ) ] 131584 K -> 47819 K ( 502784 K ) , 0.0115940 secs ] [ Times : user = 0.02 sys = 0.05 , real = 0.01 secs ] 2021 - 07 - 14 T00 : 42 : 11.676 - 0800 : 0.156 : [ GC ( Allocation Failure ) [ PSYoungGen : 153086 K -> 21497 K ( 153088 K ) ] 179403 K -> 91591 K ( 502784 K ) , 0.0159088 secs ] [ Times : user = 0.03 sys = 0.07 , real = 0.02 secs ] 2021 - 07 - 14 T00 : 42 : 11.707 - 0800 : 0.188 : [ GC ( Allocation Failure ) [ PSYoungGen : 153081 K -> 21500 K ( 153088 K ) ] 223175 K -> 131269 K ( 502784 K ) , 0.0127081 secs ] [ Times : user = 0.04 sys = 0.04 , real = 0.02 secs ] 2021 - 07 - 14 T00 : 42 : 11.736 - 0800 : 0.216 : [ GC ( Allocation Failure ) [ PSYoungGen : 153084 K -> 21503 K ( 153088 K ) ] 262853 K -> 177469 K ( 502784 K ) , 0.0151634 secs ] [ Times : user = 0.04 sys = 0.06 , real = 0.02 secs ] 2021 - 07 - 14 T00 : 42 : 11.766 - 0800 : 0.247 : [ GC ( Allocation Failure ) [ PSYoungGen : 152950 K -> 21488 K ( 153088 K ) ] 308916 K -> 218539 K ( 502784 K ) , 0.0144377 secs ] [ Times : user = 0.03 sys = 0.06 , real = 0.02 secs ] 2021 - 07 - 14 T00 : 42 : 11.797 - 0800 : 0.277 : [ GC ( Allocation Failure ) [ PSYoungGen : 152645 K -> 21497 K ( 80384 K ) ] 349697 K -> 259325 K ( 430080 K ) , 0.0132490 secs ] [ Times : user = 0.03 sys = 0.04 , real = 0.02 secs ] 2021 - 07 - 14 T00 : 42 : 11.818 - 0800 : 0.298 : [ GC ( Allocation Failure ) [ PSYoungGen : 79609 K -> 36259 K ( 116736 K ) ] 317437 K -> 280306 K ( 466432 K ) , 0.0053558 secs ] [ Times : user = 0.03 sys = 0.01 , real = 0.01 secs ] 2021 - 07 - 14 T00 : 42 : 11.833 - 0800 : 0.313 : [ GC ( Allocation Failure ) [ PSYoungGen : 95139 K -> 47999 K ( 116736 K ) ] 339186 K -> 298252 K ( 466432 K ) , 0.0076742 secs ] [ Times : user = 0.04 sys = 0.01 , real = 0.01 secs ] 2021 - 07 - 14 T00 : 42 : 11.848 - 0800 : 0.329 : [ GC ( Allocation Failure ) [ PSYoungGen : 106879 K -> 57817 K ( 116736 K ) ] 357132 K -> 316937 K ( 466432 K ) , 0.0094228 secs ] [ Times : user = 0.05 sys = 0.01 , real = 0.01 secs ] 2021 - 07 - 14 T00 : 42 : 11.866 - 0800 : 0.347 : [ GC ( Allocation Failure ) [ PSYoungGen : 116697 K -> 40221 K ( 116736 K ) ] 375817 K -> 335350 K ( 466432 K ) , 0.0127900 secs ] [ Times : user = 0.04 sys = 0.05 , real = 0.01 secs ] 2021 - 07 - 14 T00 : 42 : 11.879 - 0800 : 0.360 : [ Full GC ( Ergonomics ) [ PSYoungGen : 40221 K -> 0 K ( 116736 K ) ] [ ParOldGen : 295129 K -> 240839 K ( 349696 K ) ] 335350 K -> 240839 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0331005 secs ] [ Times : user = 0.21 sys = 0.01 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 11.922 - 0800 : 0.402 : [ GC ( Allocation Failure ) [ PSYoungGen : 58315 K -> 21801 K ( 116736 K ) ] 299155 K -> 262641 K ( 466432 K ) , 0.0018162 secs ] [ Times : user = 0.01 sys = 0.00 , real = 0.00 secs ] ...... 2021 - 07 - 14 T00 : 42 : 16.041 - 0800 : 4.521 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58880 K -> 22595 K ( 116736 K ) ] [ ParOldGen : 349642 K -> 349114 K ( 349696 K ) ] 408522 K -> 371709 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0395122 secs ] [ Times : user = 0.24 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.086 - 0800 : 4.567 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58714 K -> 26618 K ( 116736 K ) ] [ ParOldGen : 349114 K -> 349513 K ( 349696 K ) ] 407828 K -> 376131 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0603584 secs ] [ Times : user = 0.20 sys = 0.00 , real = 0.06 secs ] 2021 - 07 - 14 T00 : 42 : 16.152 - 0800 : 4.632 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58880 K -> 21695 K ( 116736 K ) ] [ ParOldGen : 349513 K -> 349492 K ( 349696 K ) ] 408393 K -> 371188 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0389743 secs ] [ Times : user = 0.20 sys = 0.01 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.198 - 0800 : 4.678 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58739 K -> 20467 K ( 116736 K ) ] [ ParOldGen : 349492 K -> 349172 K ( 349696 K ) ] 408231 K -> 369639 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0382426 secs ] [ Times : user = 0.22 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.242 - 0800 : 4.723 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58634 K -> 15899 K ( 116736 K ) ] [ ParOldGen : 349172 K -> 349690 K ( 349696 K ) ] 407806 K -> 365590 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0375539 secs ] [ Times : user = 0.22 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.288 - 0800 : 4.768 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58880 K -> 17101 K ( 116736 K ) ] [ ParOldGen : 349690 K -> 349416 K ( 349696 K ) ] 408570 K -> 366517 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0399298 secs ] [ Times : user = 0.20 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.335 - 0800 : 4.816 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58765 K -> 15555 K ( 116736 K ) ] [ ParOldGen : 349416 K -> 349180 K ( 349696 K ) ] 408182 K -> 364736 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0380655 secs ] [ Times : user = 0.21 sys = 0.01 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.381 - 0800 : 4.861 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58681 K -> 18582 K ( 116736 K ) ] [ ParOldGen : 349180 K -> 349211 K ( 349696 K ) ] 407862 K -> 367794 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0398334 secs ] [ Times : user = 0.23 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.429 - 0800 : 4.909 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58773 K -> 16686 K ( 116736 K ) ] [ ParOldGen : 349211 K -> 349040 K ( 349696 K ) ] 407985 K -> 365727 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0384315 secs ] [ Times : user = 0.20 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.474 - 0800 : 4.955 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58872 K -> 17929 K ( 116736 K ) ] [ ParOldGen : 349040 K -> 349562 K ( 349696 K ) ] 407913 K -> 367492 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0397868 secs ] [ Times : user = 0.22 sys = 0.01 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.522 - 0800 : 5.002 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58877 K -> 15917 K ( 116736 K ) ] [ ParOldGen : 349562 K -> 349348 K ( 349696 K ) ] 408440 K -> 365266 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0391023 secs ] [ Times : user = 0.22 sys = 0.00 , real = 0.04 secs ] 2021 - 07 - 14 T00 : 42 : 16.571 - 0800 : 5.051 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58597 K -> 17423 K ( 116736 K ) ] [ ParOldGen : 349348 K -> 349274 K ( 349696 K ) ] 407945 K -> 366698 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0379030 secs ] [ Times : user = 0.21 sys = 0.00 , real = 0.03 secs ] Heap PSYoungGen total 116736 K , used 19718 K [ 0 x00000007b5580000 , 0 x00000007c0000000 , 0 x00000007c0000000 ) eden space 58880 K , 33 % used [ 0 x00000007b5580000 , 0 x00000007b68c1a00 , 0 x00000007b8f00000 ) from space 57856 K , 0 % used [ 0 x00000007b8f00000 , 0 x00000007b8f00000 , 0 x00000007bc780000 ) to space 57856 K , 0 % used [ 0 x00000007bc780000 , 0 x00000007bc780000 , 0 x00000007c0000000 ) ParOldGen total 349696 K , used 349274 K [ 0 x00000007a0000000 , 0 x00000007b5580000 , 0 x00000007b5580000 ) object space 349696 K , 99 % used [ 0 x00000007a0000000 , 0 x00000007b5516a00 , 0 x00000007b5580000 ) Metaspace used 2571 K , capacity 4486 K , committed 4864 K , reserved 1056768 K class space used 276 K , capacity 386 K , committed 512 K , reserved 1048576 K
我们可以看到到ParallelGC 的GC日志和Serial GC 的日志大体结构是一致的,下面是MinorGC 的日志分析。
MinorGC 日志分析 1 2 3 4 2021 - 07 - 14 T00 : 42 : 11.676 - 0800 : 0.156 : [ GC ( Allocation Failure ) [ PSYoungGen : 153086 K -> 21497 K ( 153088 K ) ] 179403 K -> 91591 K ( 502784 K ) , 0.0159088 secs ] [ Times : user = 0.03 sys = 0.07 , real = 0.02 secs ]
日志解读如下:
2021-07-14T00:42:11.676-0800: 0.156 GC事件开始事件。GC用来区分MinorGC还是FullGC的标志,这里是一个次小型GC(MinorGC)。PSYoungGen 垃圾收集器名称。这个名字表示的是在年轻代中使用:并行GC的标记-复制(mark-copy),全线暂停(STW)垃圾收集器。153086K->21497K(153088K) 则是GC前后年轻代的使用量,以及年轻代的总大小,简单计算可以得出GC后年轻代的使用率21497K/153088K~=14%。179403K->91591K(502784K) 则是GC前后堆空间的使用量,已经可用堆的总大小,GC后堆空间的使用率为91591K/502784K~=18.2%,由于这个GC事件发生在JVM刚启动,创建的对象并不多。这个使用量还算是健康的。[Times: user=0.03 sys=0.07, real=0.02 secs] GC事件的持续事件,通过三个部分衡量:user表示GC线程所消耗的总CPU时间,sys表示操作系统调用和系统等待事件所消耗的事件。real则表示应用程序实际消耗的时间。因为不是并不是所有的操作的过程都能全部并行,所有在ParallelGC中,real~=(user+ system)/GC线程数。
通过这部分日志我们可以简单计算出:在GC之前,堆内存总使用量为179403K,其中年轻代为153086K,那么老年代的使用量为179403K-153086K=26319K这并不多,但是这是JVM的第二次GC时间,有一部分对象已经在第一次GC完成后直接被晋升进了老年代。在这次GC完成后年轻代减少了153086K-21497K=131589K,总堆减少了179403K-91591K=87812K,其中有131589K-87812K=43777K被提升到了老年代。老年代的总大小为502784K-153088K=349696K,当前老年代使用率为(91591K-21497K)/349696K~=20%。
年轻代GC,我们可以关注业务暂停时间,以及GC后内存的使用率是否正常,但不用特别关注GC前的使用量,而且只要业务在运行,年轻代的对象分配就少不了,回收量也不会少。
FullGC 日志分析 前面介绍了并行GC的年轻代的GC日志,下面我们看看老年代的GC日志。
1 2 3 4 5 6 2021 - 07 - 14 T00 : 42 : 16.571 - 0800 : 5.051 : [ Full GC ( Ergonomics ) [ PSYoungGen : 58597 K -> 17423 K ( 116736 K ) ] [ ParOldGen : 349348 K -> 349274 K ( 349696 K ) ] 407945 K -> 366698 K ( 466432 K ) , [ Metaspace : 2565 K -> 2565 K ( 1056768 K ) ] , 0.0379030 secs ] [ Times : user = 0.21 sys = 0.00 , real = 0.03 secs ]
在上面的日志中我们可以分析出以下的一些信息:
2021-07-14T00:42:16.571-0800: GC事件开始事件。Full GC 一次fullGC的标识,FullGC 表明本次GC事件清理老年代和年轻代,Ergonomics 是触发GC的原因,表示JVM内部环境认为此时可以进行一次垃圾收集。[PSYoungGen: 58597K->17423K(116736K)] 和上面的示例一样,清理年轻代的垃圾收集气是名为“PSYoungGen”的STW收集器,采用标记-复制(mark-copy)算法。年轻代使用量从58597K变为17423K,这里值得注意的是年轻代在fullGC之后并没有被清空,而是保留了部分的对象。因为这条GC日志是JVM执行后期的日志,其中老年代已经被塞的很满,不能支持这么多对象晋升。ParOldGen用于清理老年代空间的垃圾收集器类型。这里的使用的是 ParOldGen 的垃圾收集器,这是一款并行STW垃圾收集器,算法为标记-清除-整理(mark-sweep-compact)。简单计算下,GC之前老年代的使用率为 349348K/349696K~=99.9%,GC之后的老年代使用率为349274K/349696K~=99.8%,我们不难发现,fullGC并没有回收多少的内存,在这个阶段JVM在不断的进行垃圾回收,系统已经处于不可用的状态。407945K->366698K(466432K) 在垃圾收集之前和之后的堆内存的使用情况,以及可用堆内容总容量。简单分析可以知道,GC之前堆内存的使用率为:407945K/466432K~=87.5%,GC之后的堆内存为:366698K/466432K~=78.6%[Metaspace: 2565K->2565K(1056768K)]前面我们也看到了关于Metaspace 空间类似的信息,可以看出,在GC事件中Metaspace 里面没有回收任何对象。0.0379030 secs GC事件的持续时间,以秒为单位。其中[Times: user=0.21 sys=0.00, real=0.03 secs]这也是GC的持续时间,user + sys > real这是多线程执行的结果。同时这里约等于是7倍,而我的机器是4核8线程的,因为总有一定比例是不能并行执行的。
FullGC 时我们更关注老年代的使用量有没有下降,以及下降了多少 。如果FullGC之后内存不怎么下降,使用率还是很高,那就说明系统有问题了(就像我们的测试的系统一样)。
CMS 日志解读 CMS也可以称为并发标记清除垃圾收集器。其设计目的是避免老年代GC时出现长时间的卡顿。默认情况下,CMS 使用的并发线程等于CPU内核数的1/4。如果CPU资源受限,CMS的吞吐量会比ParallelGC,我们可以通过下面的选项指定CMS垃圾收集器,并将日志输出到gc.log
1 2 -XX:+UseConcMarkSweepGC -Xms512m -Xmx512m -Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
和前面分析的串行GC和并行GC一样,我们将程序启动起来,看看CMS的GC日志和前面的日志有什么不一样。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 Java HotSpot(TM) 64 -Bit Server VM (25 .231 -b11) for bsd-amd64 JRE (1.8.0_231 -b11), built on Oct 5 2019 03 :15 :25 by "java_re" with gcc 4 .2 .1 (Based on Apple Inc. build 5658 ) (LLVM build 2336.11.00 )4 k page, physical 16777216 k(395052 k free)536870912 -XX:MaxHeapSize=536870912 -XX:MaxNewSize=178958336 -XX:MaxTenuringThreshold=6 -XX:NewSize=178958336 -XX:OldPLABSize=16 -XX:OldSize=357912576 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC 2021 -07-15T01:04 :03 .885-0800 : 0 .177 : [GC (Allocation Failure) 2021 -07-15T01:04 :03 .885-0800 : 0 .177 : [ParNew: 139776 K->17471 K(157248 K), 0.0140477 secs] 139776 K->46305 K(506816 K), 0.0142076 secs] [Times: user=0 .03 sys=0 .06 , real=0 .01 secs] 2021 -07-15T01:04 :03 .919-0800 : 0 .211 : [GC (Allocation Failure) 2021 -07-15T01:04 :03 .920-0800 : 0 .212 : [ParNew: 157247 K->17466 K(157248 K), 0.0156764 secs] 186081 K->88855 K(506816 K), 0.0157774 secs] [Times: user=0 .04 sys=0 .06 , real=0 .02 secs] 2021 -07-15T01:04 :03 .953-0800 : 0 .245 : [GC (Allocation Failure) 2021 -07-15T01:04 :03 .953-0800 : 0 .245 : [ParNew: 156977 K->17471 K(157248 K), 0.0246946 secs] 228367 K->132415 K(506816 K), 0.0247922 secs] [Times: user=0 .17 sys=0 .01 , real=0 .02 secs] 2021 -07-15T01:04 :03 .995-0800 : 0 .287 : [GC (Allocation Failure) 2021 -07-15T01:04 :03 .995-0800 : 0 .287 : [ParNew: 157247 K->17470 K(157248 K), 0.0201253 secs] 272191 K->170226 K(506816 K), 0.0202300 secs] [Times: user=0 .14 sys=0 .01 , real=0 .02 secs] 2021 -07-15T01:04 :04 .031-0800 : 0 .323 : [GC (Allocation Failure) 2021 -07-15T01:04 :04 .031-0800 : 0 .323 : [ParNew: 157246 K->17472 K(157248 K), 0.0231496 secs] 310002 K->211673 K(506816 K), 0.0232433 secs] [Times: user=0 .15 sys=0 .02 , real=0 .02 secs] 2021 -07-15T01:04 :04 .054-0800 : 0 .346 : [GC (CMS Initial Mark) [1 CMS-initial-mark: 194201 K(349568 K)] 211961 K(506816 K), 0.0002540 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .054-0800 : 0 .346 : [CMS-concurrent-mark-start]2021 -07-15T01:04 :04 .056-0800 : 0 .348 : [CMS-concurrent-mark: 0.002/0 .002 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .056-0800 : 0 .348 : [CMS-concurrent-preclean-start]2021 -07-15T01:04 :04 .057-0800 : 0 .349 : [CMS-concurrent-preclean: 0.000/0 .000 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .057-0800 : 0 .349 : [CMS-concurrent-abortable-preclean-start]2021 -07-15T01:04 :04 .071-0800 : 0 .363 : [GC (Allocation Failure) 2021 -07-15T01:04 :04 .071-0800 : 0 .363 : [ParNew: 157248 K->17470 K(157248 K), 0.0241859 secs] 351449 K->252404 K(506816 K), 0.0242841 secs] [Times: user=0 .15 sys=0 .01 , real=0 .02 secs] 2021 -07-15T01:04 :04.110-0800 : 0 .402 : [GC (Allocation Failure) 2021 -07-15T01:04 :04.110-0800 : 0 .402 : [ParNew: 157246 K->17469 K(157248 K), 0.0263702 secs] 392180 K->298543 K(506816 K), 0.0264666 secs] [Times: user=0 .16 sys=0 .01 , real=0 .02 secs] 2021 -07-15T01:04 :04.151-0800 : 0 .443 : [GC (Allocation Failure) 2021 -07-15T01:04 :04.151-0800 : 0 .443 : [ParNew: 157245 K->17471 K(157248 K), 0.0225189 secs] 438319 K->339365 K(506816 K), 0.0226134 secs] [Times: user=0 .14 sys=0 .01 , real=0 .02 secs] 2021 -07-15T01:04 :04.187-0800 : 0 .479 : [GC (Allocation Failure) 2021 -07-15T01:04 :04.187-0800 : 0 .479 : [ParNew: 157247 K->157247 K(157248 K), 0.0000202 secs]2021 -07-15T01:04 :04.187-0800 : 0 .479 : [CMS2021-07-15T01 :04:04.187 -0800 : 0 .479 : [CMS-concurrent-abortable-preclean: 0.004/0 .130 secs] [Times: user=0 .53 sys=0 .04 , real=0 .13 secs] 321893 K->251462 K(349568 K), 0.0517382 secs] 479141 K->251462 K(506816 K), [Metaspace: 2565 K->2565 K(1056768 K)], 0.0518718 secs] [Times: user=0 .05 sys=0 .01 , real=0 .05 secs] 2021 -07-15T01:04 :04 .256-0800 : 0 .548 : [GC (Allocation Failure) 2021 -07-15T01:04 :04 .256-0800 : 0 .548 : [ParNew: 139630 K->17468 K(157248 K), 0.0062663 secs] 391093 K->300508 K(506816 K), 0.0063611 secs] [Times: user=0 .05 sys=0 .00 , real=0 .01 secs] 2021 -07-15T01:04 :04 .262-0800 : 0 .554 : [GC (CMS Initial Mark) [1 CMS-initial-mark: 283040 K(349568 K)] 303587 K(506816 K), 0.0001363 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .262-0800 : 0 .554 : [CMS-concurrent-mark-start]2021 -07-15T01:04 :04 .263-0800 : 0 .555 : [CMS-concurrent-mark: 0.001/0 .001 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .263-0800 : 0 .555 : [CMS-concurrent-preclean-start]2021 -07-15T01:04 :04 .264-0800 : 0 .556 : [CMS-concurrent-preclean: 0.000/0 .000 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .264-0800 : 0 .556 : [CMS-concurrent-abortable-preclean-start]2021 -07-15T01:04 :04 .277-0800 : 0 .569 : [GC (Allocation Failure) 2021 -07-15T01:04 :04 .277-0800 : 0 .569 : [ParNew: 157244 K->17471 K(157248 K), 0.0094558 secs] 440284 K->344562 K(506816 K), 0.0095346 secs] [Times: user=0 .07 sys=0 .00 , real=0 .01 secs] 2021 -07-15T01:04 :04 .287-0800 : 0 .579 : [CMS-concurrent-abortable-preclean: 0.001/0 .024 secs] [Times: user=0 .09 sys=0 .00 , real=0 .02 secs] 2021 -07-15T01:04 :04 .287-0800 : 0 .579 : [GC (CMS Final Remark) [YG occupancy: 27558 K (157248 K)]2021 -07-15T01:04 :04 .288-0800 : 0 .579 : [Rescan (parallel) , 0.0002901 secs]2021 -07-15T01:04 :04 .288-0800 : 0 .580 : [weak refs processing, 0.0000103 secs]2021 -07-15T01:04 :04 .288-0800 : 0 .580 : [class unloading, 0.0001973 secs]2021 -07-15T01:04 :04 .288-0800 : 0 .580 : [scrub symbol table, 0.0002563 secs]2021 -07-15T01:04 :04 .288-0800 : 0 .580 : [scrub string table, 0.0001485 secs][1 CMS-remark: 327091 K(349568 K)] 354649 K(506816 K), 0.0009506 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .289-0800 : 0 .580 : [CMS-concurrent-sweep-start]2021 -07-15T01:04 :04 .289-0800 : 0 .581 : [CMS-concurrent-sweep: 0.000/0 .000 secs] [Times: user=0 .01 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :04 .289-0800 : 0 .581 : [CMS-concurrent-reset-start]2021 -07-15T01:04 :04 .289-0800 : 0 .581 : [CMS-concurrent-reset: 0.000/0 .000 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .774-0800 : 5 .066 : [GC (CMS Initial Mark) [1 CMS-initial-mark: 349310 K(349568 K)] 372830 K(506816 K), 0.0002245 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .774-0800 : 5 .066 : [CMS-concurrent-mark-start]2021 -07-15T01:04 :08 .775-0800 : 5 .067 : [CMS-concurrent-mark: 0.001/0 .001 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .775-0800 : 5 .067 : [CMS-concurrent-preclean-start]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [CMS-concurrent-preclean: 0.001/0 .001 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [CMS-concurrent-abortable-preclean-start]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [CMS-concurrent-abortable-preclean: 0.000/0 .000 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [GC (CMS Final Remark) [YG occupancy: 42054 K (157248 K)]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [Rescan (parallel) , 0.0003608 secs]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [weak refs processing, 0.0000184 secs]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [class unloading, 0.0002228 secs]2021 -07-15T01:04 :08 .778-0800 : 5 .070 : [scrub symbol table, 0.0003110 secs]2021 -07-15T01:04 :08 .778-0800 : 5 .070 : [scrub string table, 0.0002060 secs][1 CMS-remark: 349310 K(349568 K)] 391364 K(506816 K), 0.0012004 secs] [Times: user=0 .01 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .778-0800 : 5 .070 : [CMS-concurrent-sweep-start]2021 -07-15T01:04 :08 .779-0800 : 5 .071 : [CMS-concurrent-sweep: 0.000/0 .000 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .779-0800 : 5 .071 : [CMS-concurrent-reset-start]2021 -07-15T01:04 :08 .779-0800 : 5 .071 : [CMS-concurrent-reset: 0.000/0 .000 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .794-0800 : 5 .086 : [GC (Allocation Failure) 2021 -07-15T01:04 :08 .794-0800 : 5 .086 : [ParNew: 157145 K->157145 K(157248 K), 0.0000216 secs]2021 -07-15T01:04 :08 .794-0800 : 5 .086 : [CMS: 349018 K->349462 K(349568 K), 0.0484635 secs] 506163 K->363671 K(506816 K), [Metaspace: 2565 K->2565 K(1056768 K)], 0.0485969 secs] [Times: user=0 .05 sys=0 .00 , real=0 .05 secs] 2021 -07-15T01:04 :08 .843-0800 : 5 .135 : [GC (CMS Initial Mark) [1 CMS-initial-mark: 349462 K(349568 K)] 363959 K(506816 K), 0.0001943 secs] [Times: user=0 .00 sys=0 .00 , real=0 .00 secs] 2021 -07-15T01:04 :08 .843-0800 : 5 .135 : [CMS-concurrent-mark-start]157248 K, used 19849 K [0 x00000007a0000000 , 0 x00000007aaaa0000, 0 x00000007aaaa0000)139776 K, 14 % used [0 x00000007a0000000 , 0 x00000007a13627d0 , 0 x00000007a8880000 )17472 K, 0 % used [0 x00000007a9990000 , 0 x00000007a9990000 , 0 x00000007aaaa0000)17472 K, 0 % used [0 x00000007a8880000 , 0 x00000007a8880000 , 0 x00000007a9990000 )349568 K, used 349462 K [0 x00000007aaaa0000, 0 x00000007c0000000 , 0 x00000007c0000000 )2571 K, capacity 4486 K, committed 4864 K, reserved 1056768 K276 K, capacity 386 K, committed 512 K, reserved 1048576 K
以上是CMS的一部分GC日志,相比于串行GC/并行GC来说,CMS 的日志信息复杂了很多,这一方面是因为CMS拥有更加精细的GC步骤,另一方面GC日志很详细就意味着暴露出来的问题也更加全面细致。
MinorGC 日志分析 其中GC详情的前面几行是年轻代MinorGC时间。
1 2 3 4 5 6 2021 -07 -15 T01 :04 :03 .885 -0800 : 0 .177 : 2021 -07 -15 T01 :04 :03 .885 -0800 : 0 .177 : 139776K ->46305 K(506816 K), 0 .0142076 secs]
2021-07-15T01:04:03.885-0800: 0.177: GC事件开始的事件。GC (Allocation Failure) 用来区分MinorGC还是FullGC的标志。GC 表明这是一次小型GC;Allocation Failure表示触发GC的原因。本次GC事件,是由年轻代可用空间不足,新对象的内存分配失败引起的。[ParNew: 139776K->17471K(157248K), 0.0140477 secs] 其中ParNew是垃圾收集器的名称,对应的就是前面打印的-XX:+UseParNewGC这个命令行标志。表示年轻代中使用的:并行的标记-复制(mark-copy)垃圾收集器,专门设计了用来配合CMS 的垃圾收集器,因为CMS只负责回收老年代。后面的数字表示GC前后的年轻代使用量变化,以及年轻代的总大小。0.0140477 secs是消耗的时间。139776K->46305K(506816K), 0.0142076 secs 表示GC前后堆内存的使用量变化,以及堆空间的内存大小。消耗时间是0.0142076 secs,和前面的 ParNew 部分的时间基本上一样。[Times: user=0.03 sys=0.06, real=0.01 secs] GC事件的持续事件,user是GC线程所消耗的总CPU时间:sys 是操作系统调用和系统等待事件消耗的事件;应用程序实际暂停时间real ~= (user + sys)/GC线程数。
通过进一步计算我们可以知道,在GC之前,年轻代是使用量为 139776K/157248K ~= 88.9%。堆内存的使用率为139776K/506816K ~= 27.6%,简单估算下老年代的使用量,在ParNew GC 开始前,年轻代和整堆使用量相同因此,老年代在GC之前的使用量为0。而GC后老年代的使用率为(46305-17471)/506816K~=5.6%。
FullGC 日志分析 CMS 的日志风格和之前的集中日志的风格不一样,CMS的日志包含了CMS执行的多个阶段的内存使用信息,同时也包含了更多更详细的GC信息,下面就是一条完整的GC日志信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 2021-07 -15 T01:04:08.774-0800 : 5.066: -07 -15 T01:04:08.774-0800 : 5.066: [CMS-concurrent-mark-start]-07 -15 T01:04:08.775-0800 : 5.067: -07 -15 T01:04:08.775-0800 : 5.067: [CMS-concurrent-preclean-start]-07 -15 T01:04:08.777-0800 : 5.069: -07 -15 T01:04:08.777-0800 : 5.069: [CMS-concurrent-abortable-preclean-start]-07 -15 T01:04:08.777-0800 : 5.069: -07 -15 T01:04:08.777-0800 : 5.069: [GC (CMS Final Remark) [YG occupancy: 42054 K (157248 K)]-07 -15 T01:04:08.777-0800 : 5.069: [Rescan (parallel) , 0.0003608 secs]-07 -15 T01:04:08.777-0800 : 5.069: [weak refs processing, 0.0000184 secs]-07 -15 T01:04:08.777-0800 : 5.069: [class unloading, 0.0002228 secs]-07 -15 T01:04:08.778-0800 : 5.070: [scrub symbol table, 0.0003110 secs]-07 -15 T01:04:08.778-0800 : 5.070: [scrub string table, 0.0002060 secs]-07 -15 T01:04:08.778-0800 : 5.070: [CMS-concurrent-sweep-start]-07 -15 T01:04:08.779-0800 : 5.071: -07 -15 T01:04:08.779-0800 : 5.071: [CMS-concurrent-reset-start]-07 -15 T01:04:08.779-0800 : 5.071:
在实际的运行阶段,CMS在进行老年代的并发垃圾回收时,可能伴随多次年轻代的MinorGC,在这种情况下,FullGC的日志中可能掺杂多次MinorGC事件。接下来我们会详细分析CMS日志的每个部分,如果又忘记的小伙伴可以去垃圾收集器(上)复习下CMS的垃圾收集过程。
阶段1:Initial Mark(初始标记) 前面提到过,这个阶段伴随着STW暂停。初始标记的目标是标记所有的根对象,包括GC ROOT直接引用的对象,以及被年轻代中所有存活对象所引用的对象。后面这部分也非常重要,因为老年代是独立进行回收的。先看这个阶段的日志信息。
1 2 3 4 2021-07-15T01:04:08.774-0800: 5.066: user =0.00 sys =0.00, real =0.00 secs]
2021-07-15T01:04:08.774-0800: 5.066: GC开始事件,这个部分就不重复。CMS Initial Mark这个阶段的名称为 “Initial Mark”,会标记所有的GC ROOT。[1 CMS-initial-mark: 349310K(349568K)] 这个部分数字表示老年代的使用量,以及老年代的空间大小。372830K(506816K), 0.0002245 secs 这个是当前堆内存的使用量,以及可用堆的大小,消耗的时间,可以看出这个时间非常短,只有0.02毫秒,因为要标记的Root数量非常少。[Times: user=0.00 sys=0.00, real=0.00 secs] 初始标记时间暂停的时间,我们可以看到耗费时间非常短,基本可以忽略不计。
阶段2:Concurrent Mark(并发标记) 在并发标记阶段,CMS 从前一段 “Inital Mark”找到ROOT开始算起,遍历老年代并标记所有的存活对象。这个阶段的GC日志如下:
1 2 3 4 2021-07-15T01:04:08.774-0800: 5.066: [CMS-concurrent-mark-start]user =0.00 sys =0.00, real =0.00 secs]
CMS-concurrent-mark-start -指明了是CMS垃圾收集器所处的阶段为并发标记”Concurrent Mark”。0.001/0.001 secs 此阶段的持续时间,分别是GC线程消耗的时间和实际消耗的时间。[Times: user=0.00 sys=0.00, real=0.00 secs] 执行实现对并发阶段来说并没有多少意义,因为是从并发标记开始时刻计算的,而这段时间应用线程也在执行,所以这个时间只是一个大概的值。
阶段3:Concurrent Preclean(并发预清理) 此阶段同样是与应用线程并发执行的,不需要停止应用线程。这阶段的并发日志如下:
1 2 3 4 2021-07-15T01:04:08.775-0800: 5.067: [CMS-concurrent-preclean-start]user =0.00 sys =0.00, real =0.00 secs]
简单解读:
CMS-concurrent-preclean 表明这是并发清理阶段的日志,这个阶段会统计前面的并发标阶段执行过程中发生了改变的对象。0.001/0.001 secs 此阶段的持续时间,分别是GC线程运行时间和实际占用的时间。Times部分和前面的一样这里就不重复介绍了。
阶段4:Concurrent Abortable Preclean(可取消的并发预清理) 此阶段也不停止应用线程,尝试在就触发STW的Final Remark 阶段开始之前,尽可能地多干一些活。本阶段的具体时间取决于多种因素,因为它循环做同样的事情,直到满足某一个退出条件(如迭代次数,有用工作量,消耗的系统时间等等)。以下是GC日志:
1 2 3 4 2021-07-15T01:04:08.777-0800: 5.069: [CMS-concurrent-abortable-preclean-start]user =0.00 sys =0.00, real =0.00 secs]
解读如下:
CMS-concurrent-abortable-preclean 表明此阶段的名称:Concurrent-Abortable-Preclean。0.000/0.000 secs 此阶段GC线程的运行时间和实际占用时间,本质上来说,GC线程试图在执行STW暂停之前等待尽可能长的时间,默认条件下,此阶段可以持续最长5秒钟的时间。
此阶段完成的工作可能对STW停顿时间有较大的影响,并且有许多的重要配置选项和失败模式。
最终标记是此次GC事件中的第二次(也是最后一次)STW停顿。本阶段的目标是完成老年代的所有存活对象的标记。因为之前的预清理阶段是并发执行的,有可能GC线程跟不上应用线程的修改速度,所以需要一次STW暂停来处理各种复杂的情况。通常CMS会尝试在年轻代尽可能空的情况下执行final remark阶段,以避免连续触发多次STW时间。以下是这个部分的日志。
1 2 3 4 5 6 7 8 2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [GC (CMS Final Remark) [YG occupancy: 42054 K (157248 K)]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [Rescan (parallel) , 0.0003608 secs]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [weak refs processing, 0.0000184 secs]2021 -07-15T01:04 :08 .777-0800 : 5 .069 : [class unloading, 0.0002228 secs]2021 -07-15T01:04 :08 .778-0800 : 5 .070 : [scrub symbol table, 0.0003110 secs]2021 -07-15T01:04 :08 .778-0800 : 5 .070 : [scrub string table, 0.0002060 secs]1 CMS-remark: 349310 K(349568 K)] 391364 K(506816 K), 0.0012004 secs] 0 .01 sys=0 .00 , real=0 .00 secs]
CMS Final Remark 这是此阶段的名称,最终标记阶段。会标记老年代中所有的存活对象,包括此前的并发标记过程中创建/修改的引用。YG occupancy: 42054 K (157248 K) 当前年轻代的使用量和总容量。[Rescan (parallel) , 0.0003608 secs] 在程序暂停后进行重新扫描(Rescan),以完成存活对象的标记,这部分是并行执行的,消耗的时间为0.0003608 secs。[weak refs processing, 0.0000184 secs]这是第一个子阶段:处理弱引用的持续时间。class unloading, 0.0002228 secs 第二个子阶段:卸载不使用的类,以及持续时间。scrub symbol table, 0.0003110 secs 第三个子阶段:清理符号表,即持有class级别metadata 的符号表(symbol tables)。scrub string table, 0.0002060 secs第四个子阶段:清理内联的字符串对应的String tables。CMS-remark: 349310K(349568K) 此阶段完成后老年代的使用量和总容量。391364K(506816K), 0.0012004 secs 此阶段完成后,整个内存堆的使用量和总容量。[Times: user=0.01 sys=0.00, real=0.00 secs] GC事件的持续时间。
在这5个阶段完成后,老年代中的所有对象都被标记上,接下来JVM会将所有不使用的对西那个清除,以回收老年代空间。
阶段6:Concurrent Sweep(并发清除) 这个阶段与应用程序并发执行,不需要STW停顿,目的是删除不再使用的对象,并回收他们占用的空间。以下是这部分的GC日志。
1 2 3 4 2021-07-15T01:04:08.778-0800: 5.070: [CMS-concurrent-sweep-start]user =0.00 sys =0.00, real =0.00 secs]
简单解读:
CMS-concurrent-sweep 这是这个阶段的名字“concurrent-sweep”,并发清除老年代中所有未被标记的对象,也就是不再使用的对象,以释放内存空间。0.000/0.000 secs 此阶段的持续时间和实际占用的时间,这是一个四舍五入的值,只精确到小数点后3位。
阶段7:Concurrent Reset(并发重置) 此阶段与应用程序线程并发执行,重置CMS算法相关的内部数据结构,下一次触发GC时就可以直接使用。这个阶段的日志如下:
1 2 3 4 2021-07-15T01:04:08.779-0800: 5.071: [CMS-concurrent-reset-start]user =0.00 sys =0.00, real =0.00 secs]
简单解读如下:
CMS-concurrent-reset 此阶段的名称,“Concurrent Reset”,重置CMS算法的内部数据结构,为以下此GC循环做准备。0.000/0.000 secs 此阶段的持续时间和实际占用时间。
总之,CMS垃圾收集器在减少停顿时间上做出了很多给力的工作,很大一部分GC线程与应用线程并发运行的,不需要暂停应用线程,这样就可以在一般情况下每次暂停的时间较少。当然,CMS也有一些缺点,其中最大的问题就是老年代的内存碎片问题,在某个情况下GC会有不可预测的暂停时间,特别是堆内存比较大的情况下。CMS 的原理与解析可以看我们复习我们前面的垃圾收集器(上)。
G1 日志解读 如果对于G1的垃圾收集器的收集过程和原理不熟悉的同学也可以复习我们前面总结的垃圾收集器(上)。使用如下JVM参数启动。
1 -XX:+UseG1GC -Xloggc:gc.log -XX:+PrintGCDetails -XX:+PrintGCDateStamps
使用GC垃圾收集器我们可以得到如下的日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 ava HotSpot(TM) 64 -Bit Server VM (25.231 -b11) for bsd-amd64 JRE (1.8 .0 _231-b11), built on Oct 5 2019 03 :15 :25 by "java_re" with gcc 4.2 .1 (Based on Apple Inc. build 5658 ) (LLVM build 2336.11 .00 )4 k page, physical 16777216 k(588376 k free)proc /meminfo: flags: -XX:InitialHeapSize=536870912 -XX:MaxHeapSize=536870912 -XX:+PrintGC -XX:+PrintGCDateStamps -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC pause (G1 Evacuation Pause) (young), 0.0035596 secs] Time: 2.8 ms, GC Workers: 8] Worker Start (ms): Min: 77.4, Avg: 77.5, Max: 77.5, Diff: 0.1] Root Scanning (ms): Min: 0.1, Avg: 0.2, Max: 0.8, Diff: 0.7, Sum: 1.8] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Buffers: Min: 0, Avg: 0.0, Max: 0, Diff: 0, Sum: 0] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Copy (ms): Min: 1.5, Avg: 1.7, Max: 1.8, Diff: 0.3, Sum: 13.5] Min: 0.3, Avg: 0.7, Max: 0.8, Diff: 0.4, Sum: 5.3] Attempts: Min: 1, Avg: 4.4, Max: 7, Diff: 6, Sum: 35] Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] Worker Total (ms): Min: 2.5, Avg: 2.6, Max: 2.7, Diff: 0.2, Sum: 20.8] Worker End (ms): Min: 80.0, Avg: 80.0, Max: 80.2, Diff: 0.2] Root Fixup: 0.0 ms] Root Purge: 0.0 ms] CT: 0.1 ms] ms] CSet: 0.0 ms] Proc: 0.2 ms] Enq: 0.0 ms] Cards: 0.1 ms] Register: 0.0 ms] Reclaim: 0.0 ms] CSet: 0.0 ms] Survivors: 0.0B->4096.0K Heap: 28.6M(512.0M)->8908.2K(512.0M)] user=0.01 sys=0.01, real=0.00 secs] pause (G1 Humongous Allocation) (young) (initial-mark), 0.0044054 secs] Time: 4.0 ms, GC Workers: 8] Worker Start (ms): Min: 292.0, Avg: 292.1, Max: 292.1, Diff: 0.1] Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.1, Sum: 0.6] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.2] Buffers: Min: 1, Avg: 1.2, Max: 2, Diff: 1, Sum: 10] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Copy (ms): Min: 3.6, Avg: 3.7, Max: 3.7, Diff: 0.1, Sum: 29.2] Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.6] Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8] Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] Worker Total (ms): Min: 3.8, Avg: 3.8, Max: 3.9, Diff: 0.1, Sum: 30.8] Worker End (ms): Min: 295.9, Avg: 295.9, Max: 296.0, Diff: 0.1] Root Fixup: 0.0 ms] Root Purge: 0.0 ms] CT: 0.1 ms] ms] CSet: 0.0 ms] Proc: 0.1 ms] Enq: 0.0 ms] Cards: 0.1 ms] Register: 0.0 ms] Reclaim: 0.0 ms] CSet: 0.0 ms] Survivors: 33.0M->1024.0K Heap: 307.5M(512.0M)->305.7M(512.0M)] user=0.02 sys=0.00, real=0.01 secs] concurrent-root-region-scan-start] 2021-07-21T00:45:17.542-0800: 0.296: [GC concurrent-root-region-scan-end, 0.0000326 secs] 2021-07-21T00:45:17.542-0800: 0.296: [GC concurrent-mark-start] 2021-07-21T00:45:17.544-0800: 0.298: [GC concurrent-mark-end, 0.0019507 secs] 2021-07-21T00:45:17.544-0800: 0.299: [GC remark 2021-07-21T00:45:17.544-0800: 0.299: [Finalize Marking, 0.0002050 secs] 2021-07-21T00:45:17.544-0800: 0.299: [GC ref-proc, 0.0000344 secs] 2021-07-21T00:45:17.544-0800: 0.299: [Unloading, 0.0003887 secs], 0.0010297 secs] user=0.00 sys=0.00, real=0.00 secs] cleanup 319M->319M(512M), 0.0007032 secs] user=0.01 sys=0.00, real=0.00 secs] pause (G1 Evacuation Pause) (young) (to-space exhausted), 0.0032034 secs] Time: 2.3 ms, GC Workers: 8] Worker Start (ms): Min: 323.3, Avg: 323.4, Max: 323.4, Diff: 0.2] Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.7] RS (ms): Min: 0.1, Avg: 0.2, Max: 0.3, Diff: 0.2, Sum: 1.4] Buffers: Min: 0, Avg: 2.4, Max: 3, Diff: 3, Sum: 19] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Copy (ms): Min: 1.6, Avg: 1.8, Max: 1.8, Diff: 0.2, Sum: 14.3] Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.2] Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8] Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] Worker Total (ms): Min: 2.0, Avg: 2.1, Max: 2.2, Diff: 0.2, Sum: 16.9] Worker End (ms): Min: 325.5, Avg: 325.5, Max: 325.5, Diff: 0.0] Root Fixup: 0.0 ms] Root Purge: 0.0 ms] CT: 0.1 ms] ms] Failure: 0.5 ms] CSet: 0.0 ms] Proc: 0.1 ms] Enq: 0.0 ms] Cards: 0.1 ms] Register: 0.0 ms] Reclaim: 0.0 ms] CSet: 0.0 ms] Survivors: 1024.0K->15.0M Heap: 455.3M(512.0M)->412.4M(512.0M)] user=0.01 sys=0.01, real=0.01 secs] pause (G1 Evacuation Pause) (mixed), 0.0028130 secs] Time: 2.4 ms, GC Workers: 8] Worker Start (ms): Min: 328.6, Avg: 328.6, Max: 328.7, Diff: 0.1] Root Scanning (ms): Min: 0.0, Avg: 0.1, Max: 0.1, Diff: 0.1, Sum: 0.6] RS (ms): Min: 0.1, Avg: 0.2, Max: 0.2, Diff: 0.1, Sum: 1.3] Buffers: Min: 0, Avg: 2.2, Max: 3, Diff: 3, Sum: 18] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Copy (ms): Min: 1.9, Avg: 1.9, Max: 2.0, Diff: 0.2, Sum: 15.5] Min: 0.0, Avg: 0.1, Max: 0.2, Diff: 0.2, Sum: 0.7] Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8] Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.1] Worker Total (ms): Min: 2.2, Avg: 2.3, Max: 2.3, Diff: 0.1, Sum: 18.3] Worker End (ms): Min: 330.9, Avg: 330.9, Max: 331.0, Diff: 0.1] Root Fixup: 0.0 ms] Root Purge: 0.0 ms] CT: 0.1 ms] ms] CSet: 0.0 ms] Proc: 0.1 ms] Enq: 0.0 ms] Cards: 0.1 ms] Register: 0.0 ms] Reclaim: 0.0 ms] CSet: 0.0 ms] Survivors: 15.0M->4096.0K Heap: 425.6M(512.0M)->365.1M(512.0M)] user=0.01 sys=0.00, real=0.00 secs] pause (G1 Evacuation Pause) (young), 0.0006462 secs] Time: 0.3 ms, GC Workers: 8] Worker Start (ms): Min: 5032.5, Avg: 5032.6, Max: 5032.6, Diff: 0.0] Root Scanning (ms): Min: 0.1, Avg: 0.1, Max: 0.1, Diff: 0.0, Sum: 0.7] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.1, Diff: 0.1, Sum: 0.2] Buffers: Min: 0, Avg: 0.9, Max: 1, Diff: 1, Sum: 7] RS (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Root Scanning (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Copy (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Min: 0.0, Avg: 0.2, Max: 0.2, Diff: 0.2, Sum: 1.3] Attempts: Min: 1, Avg: 1.0, Max: 1, Diff: 0, Sum: 8] Worker Other (ms): Min: 0.0, Avg: 0.0, Max: 0.0, Diff: 0.0, Sum: 0.0] Worker Total (ms): Min: 0.2, Avg: 0.3, Max: 0.3, Diff: 0.1, Sum: 2.3] Worker End (ms): Min: 5032.8, Avg: 5032.8, Max: 5032.9, Diff: 0.1] Root Fixup: 0.0 ms] Root Purge: 0.0 ms] CT: 0.1 ms] ms] CSet: 0.0 ms] Proc: 0.1 ms] Enq: 0.0 ms] Cards: 0.1 ms] Register: 0.1 ms] Reclaim: 0.0 ms] CSet: 0.0 ms] Survivors: 0.0B->0.0B Heap: 405.6M(512.0M)->405.6M(512.0M)] user=0.00 sys=0.00, real=0.00 secs] GC (Allocation Failure) 405M->378M(512M), 0.0339622 secs] Survivors: 0.0B->0.0B Heap: 405.6M(512.0M)->378.8M(512.0M)], [Metaspace: 2565K->2565K(1056768K)] user=0.03 sys=0.00, real=0.04 secs] concurrent-mark-abort] Heap heap total 524288K, used 387912K [0x00000007a0000000, 0x00000007a0101000, 0x00000007c0000000) region size 1024K, 1 young (1024K), 0 survivors (0K) Metaspace used 2571K, capacity 4486K, committed 4864K, reserved 1056768K class space used 276K, capacity 386K, committed 512K, reserved 1048576K
以上是一部分G1的GC日志信息,实际上我们程序运行了几秒中却生成了1MB多的日志数据,由此可见G1输出的日志真的很多。其中我们主要能看到以下几种GC类型。
Evacuation Pause:young(纯年轻代模式转移暂停) 当年轻代空间用满后,应用线程会被暂停,年轻代内存块中的存活对象被拷贝到存活区。如果还没有存活区,则任意选择一部分空闲内存块作为存活区。拷贝的过程被称为转移(Evacuation),这和前面介绍的其他年轻代收集器是一样的工作原理。由于日志记录非常多,所以并行阶段和“其他”阶段的日志将拆分多个部分解析。
1 2 3 4 5 6 7 8 9 10 2021-07-21T00:45:17.323-0800: 0.077: [GC pause (G1 Evacuation Pause) (young) , 0.0035596 secs ]Parallel Time: 2.8 ms , GC Workers: 8 ]...GC work thread Code Root Fixup: 0.0 ms ]Code Root Purge: 0.0 ms ]Clear CT: 0.1 ms ]Other: 0.6 ms ]...other job Eden: 25. 0M(25.0M)->0.0B(27.0M) Survivors: 0. 0B->4096.0K Heap: 28. 6M(512.0M)->8908.2K(512.0M) ]Times: user=0.01 sys=0.01 , real=0.00 secs ]
日志分析如下:
[GC pause (G1 Evacuation Pause) (young), 0.0035596 secs] G1转移暂停,纯年轻代模式:只清理年轻空间。这次暂停在JVM启动之后77ms开始,持续的系统时间为:0.0035596 secs,也就是3.5ms。[Parallel Time: 2.8 ms, GC Workers: 8] 表明后面的活动由8个Worker 线程并行执行,消耗时间为2.8ms(real time);worker是一种模式,类似于一个老板指挥多个工人干活,类似与Netty的 BossGroup 和 WorkerGroup。[Code Root Fixup: 0.0 ms] 释放用于管理并行活动的内部数据,一般都接近于零。这个过程是串行执行的。[Code Root Purge: 0.0 ms] 清理其他部分数据,也是非常快的,如非必要基本上等于零,也是串行的执行的过程。[Other: 0.6 ms] 其他活动消耗的时间,其中大部分都是并行的。[Eden: 25.0M(25.0M)->0.0B(27.0M) 暂停之前和暂停之后,Eden区的使用量/总容量。Survivors: 0.0B->4096.0K GC暂停前后,存活区的使用量。Heap: 28.6M(512.0M)->8908.2K(512.0M)] 暂停前后整个堆内存的使用量和总容量。[Times: user=0.01 sys=0.01, real=0.00 secs] GC事件的持续事件。
系统事件(wall clock time/elapsed time),是指一段程序从运行到终止,系统时钟走过的时间,一般系统时间比CPU时间略微长一点。
1 2 3 4 5 6 7 8 9 10 11 12 13 [Parallel Time: 2.3 ms, GC Workers: 8 ]323.3 , Avg: 323.4 , Max: 323.4 , Diff: 0.2 ]0.0 , Avg: 0.1 , Max: 0.2 , Diff: 0.2 , Sum: 0.7 ]0.1 , Avg: 0.2 , Max: 0.3 , Diff: 0.2 , Sum: 1.4 ]0 , Avg: 2.4 , Max: 3 , Diff: 3 , Sum: 19 ]0.0 , Avg: 0.0 , Max: 0.0 , Diff: 0.0 , Sum: 0.1 ]0.0 , Avg: 0.0 , Max: 0.0 , Diff: 0.0 , Sum: 0.0 ]1.6 , Avg: 1.8 , Max: 1.8 , Diff: 0.2 , Sum: 14.3 ]0.0 , Avg: 0.0 , Max: 0.1 , Diff: 0.1 , Sum: 0.2 ]1 , Avg: 1.0 , Max: 1 , Diff: 0 , Sum: 8 ]0.0 , Avg: 0.0 , Max: 0.0 , Diff: 0.0 , Sum: 0.1 ]2.0 , Avg: 2.1 , Max: 2.2 , Diff: 0.2 , Sum: 16.9 ]325.5 , Avg: 325.5 , Max: 325.5 , Diff: 0.0 ]
上面这段日志是省略的工作线程的日志信息,简单的解读如下:
[Parallel Time: 2.3 ms, GC Workers: 8] 前面介绍过,这表明下列活动由8个线程并行执行,消耗的时间为2.3ms(real time)。GC Worker Start(ms) GC的worker线程开始启动时,相当于 pause 开始时间的毫秒间隔,如果Min和Max差别很大,则表明本机其他进程所使用的线程数量过多,挤占了GC的可用CPU时间。Ext Root Scanning(ms) 用了多长时间来扫描堆外内存(non-heap) 的GC ROOT,如classloader,JNI引用,JVM系统ROOT等。后面显示了运行时间,“Sum”指的是CPU时间。Update RS,Processed Buffers,Scan RS这三部分也是类似的,RS是Remember Set的缩写。Code Root Scanning(ms) 扫描实际代码中的 root 用了多长时间:例如线程栈中的局部变量。Object Copy(ms) 用了多长时间来拷贝回收集中的存活对象。Tremination(ms) GC 的worker线程用了多长时间来确保自身可以安全地停止,这段时间内什么都不做,完成后GC线程就终止了,所以叫终止等待。Termination Attempts GC的 woker 线程尝试多少次 try 和 teminate。如果 worker 发现还有一些任务没有处理完,则这一次尝试就是失败的,暂时还不能终止。GC Worker Other (ms) 其他的一些小任务,因为时间很短,在GC日志将他们归结在一起。GC Worker Total (ms) GC的worker线程工作总计。GC Worker End (ms) GC的worker线程完成作业的时刻,相对于此次GC暂停开始时间的毫秒数。通常来说这部分数字应该大致相等,否则就说明有太多的线程被挂起。
除此之外,在转移暂停期间还有一些琐碎的小任务。
1 2 3 4 5 6 7 8 [Other: 0.6 ms]0.0 ms]0.2 ms]0.0 ms]0.1 ms]0.0 ms]0.0 ms]0.0 ms]
其他琐碎任务,这里只介绍其中一部分:
[Other: 0.6 ms] 其他活动消耗的时间,其中很多是并行执行的。[Choose CSet: 0.0 ms] 选择CSet消耗的时间,CSet 是Colletion Set 的缩写。[Ref Proc: 0.2 ms] 处理非强引用(non-strong)的时间:进行清理或者决定是否需要清理。[Ref Enq: 0.0 ms] 用来将剩下的 non-strong 引用排序到合适的 ReferenceQueue 中。[Humongous Register: 0.0 ms],[Humongous Reclaim: 0.0 ms] 大对象相关部分。[Free CSet: 0.0 ms] 将回收集中被释放的小堆归还所消耗的时间,以便给他们能用来分配新对象。
Concurrent Marking(并发标记) 当堆内存的总体使用达到一定的数值时,就会触发并发标记。这个默认比例是45%,但也可以通过JVM参数InitialtingHeapOccupancyPercent 来设置。和CMS一样,G1的并发标记也是由多个阶段组成,其中一些阶段是完成并发的,还有一些阶段则会暂停应用线程。如下是并发标记的日志信息:
1 2 3 4 5 6 7 8 9 10 11 12 2021-07 -21 T00:45:17.538-0800 : 0.292: [GC pause (G1 Humongous Allocation) (young) (initial-mark), 0.0044054 secs]-07 -21 T00:45:17.542-0800 : 0.296: [GC concurrent-root-region-scan-start]-07 -21 T00:45:17.542-0800 : 0.296: [GC concurrent-root-region-scan-end, 0.0000326 secs]-07 -21 T00:45:17.542-0800 : 0.296: [GC concurrent-mark-start]-07 -21 T00:45:17.544-0800 : 0.298: [GC concurrent-mark-end, 0.0019507 secs]-07 -21 T00:45:17.544-0800 : 0.299: [GC remark 2021-07 -21 T00:45:17.544-0800 : 0.299: [Finalize Marking, 0.0002050 secs] -07 -21 T00:45:17.544-0800 : 0.299: [GC ref-proc, 0.0000344 secs] -07 -21 T00:45:17.544-0800 : 0.299: [Unloading, 0.0003887 secs], 0.0010297 secs]-07 -21 T00:45:17.545-0800 : 0.300: [GC cleanup 319M->319M(512M), 0.0007032 secs]
阶段1:Initial Mark(初始标记) 以下是这次GC事件的开始,我们不难发现这是因为大对象的分配导致的GC。初始标记日志如下:
1 2 2021 -07-21T00:45 :17 .538-0800 : 0 .292 : 0.0044054 secs]
阶段2:Root Region Scan(Root区扫描) 此阶段从Root开始标记扫描可达对象。以下是对应的日志信息。
1 2 3 4 2021-07 -21 T00:45:17.542-0800 : 0.296: -07 -21 T00:45:17.542-0800 : 0.296:
阶段3:Concurrent Mark(并发标记) 以下是并发标记阶段的日志输出。
1 2 3 4 2021-07 -21 T00:45:17.542-0800 : 0.296: -07 -21 T00:45:17.544-0800 : 0.298:
阶段4:Final mark(最终标记) 对应的日志信息。
1 2 3 4 5 6 7 8 9 2021 -07-21T00:45 :17 .544-0800 : 0 .299 : 2021 -07-21T00:45 :17 .544-0800 : 0 .299 : 0.0002050 secs] 2021 -07-21T00:45 :17 .544-0800 : 0 .299 : 0.0000344 secs] 2021 -07-21T00:45 :17 .544-0800 : 0 .299 : 0.0003887 secs], 0.0010297 secs]0 .00 sys=0 .00 , real=0 .00 secs]
阶段5:Cleanup(清理) 最后这个清理阶段为即将到来的转移阶段作准备,统计小堆块中所有存活的对象,并将小堆块进行排序,以提高GC效率。这个阶段也为下一次标记执行必需的所有整理工作(house-keeping activites):维护并发标记的内部状态。要注意的是,所有包括存活对象的小堆块在此阶段都被回收了。有一部分任务是并发的,例如空堆区的回收,还有大部分的存活率计算,此阶段也需要一个短暂的STW,才能不受应用线程的影响并完成作业,对应日志如下:
1 2021 -07 -21 T00 :45 :17 .545 -0800 : 0 .300 : [GC cleanup 319M->319M(512M), 0.0007032 secs]
Evacuation Pause(mixed)(转移暂停:混合模式) 并发标记完成之后,G1将执行一次混合收集(mixed collection),不只清理年轻代,还将一部分老年代区域也加入到collection set中。混合模式的转移暂停(Evacuation pause)不一定紧跟并发标记阶段。在并发标记与混合转移暂停之间,很可能会存在多次 young 模式的转移暂停。
混合模式 就是指这次GC事件混合着处理年轻代和老年代的region。这也是G1等增量垃圾收集器的特色。而ZGC等最新的垃圾收集器则不使用分代算法。
混合模式下的日志,和纯年轻代模式相比,还是有一些区别的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 2021-07-21T00:45:17.574-0800: 0.328: GC pause (G1 Evacuation Pause) (mixed) , 0.0028130 secs ]Parallel Time: 2.4 ms , GC Workers: 8 ]...... Update RS (ms): Min: 0.0 , Avg: 0.0 , Max: 0.1 , Diff: 0.1 , Sum: 0.2 ]Processed Buffers: Min: 0 , Avg: 0.9 , Max: 1 , Diff: 1 , Sum: 7 ]Scan RS (ms): Min: 0.0 , Avg: 0.0 , Max: 0.0 , Diff: 0.0 , Sum: 0.0 ]...... Code Root Fixup: 0.0 ms ]Code Root Purge: 0.0 ms ]Clear CT: 0.1 ms ]Other: 0.3 ms ]Choose CSet: 0.0 ms ]Ref Proc: 0.1 ms ]Ref Enq: 0.0 ms ]Redirty Cards: 0.1 ms ]Humongous Register: 0.0 ms ]Humongous Reclaim: 0.0 ms ]Free CSet: 0.0 ms ]Eden: 10. 0M(10.0M)->0.0B(21.0M) Survivors: 15. 0M->4096.0K Heap: 425. 6M(512.0M)->365.1M(512.0M) ]Times: user=0.01 sys=0.00 , real=0.00 secs ]
简单解读如下(部分概念和名称,可以参考前面的G1的日志分析):
Update RS (ms) 因为 Remember Sets 是并发处理的,必须确保在实际的垃圾收集之前,缓冲区中的card 的得到处理,如果card数量很多,则GC并发线程的负载可能就会很高。可能的原因是修改的字段过多,或CPU资源受限。Processed Buffers 各个worker 线程处理了多个本地缓冲区(local buffer)。Scan RS (ms) 用了多长时间扫描来自RSet的引用。[Clear CT: 0.1 ms] 清理 card table 中的 cards 的时间。清理工作只是简单地删除“脏”状态,此状态用来标识一个字段是否被更新,供Remebered Sets 使用。[Redirty Cards: 0.1 ms] 将 card table 中适当的位置标记为 dirty 所花费的时间。
Full GC(Allocation Failure) G1 是一款自适应的增量垃圾收集器。一般来说,只有在内存严重不足的情况下才会发生 FullGC,以下即是这部分的日志输出结果。
1 2 3 4 5 6 2021 -07 -21 T00:45 :22.279 -0800 : 5.033 : ull GC (Allocation Failure) 405M->378 M(512 M), 0.0339622 secs]den : 0.0B(25.0M)->0.0 B(25.0 M) urvivors : 0.0B->0.0 B Heap : 405.6M(512.0M)->378.8 M(512.0 M)], etaspace : 2565K->2565 K(1056768 K)]0.03 sys=0.00 , real =0.04 secs]
GC调优 我们的GC有很多的默认参数,基本能满足我们大多数的场景下的性能需求。但是在一些场景下我们的硬件条件并不是那么充足,或者说是在一些默认的场景下JVM不能满足我们的个别性能点需求。因此我们需要通过观察分析GC日志调整GC参数的方式,让JVM在特定的场景表现出最优的性能表现。那么GC调优我们该怎么开始呢?
我刚接触GC调优的时候,我对GC调优无从下手,面对那么多参数,怎么才算是调优了呢?换一个垃圾收集器,堆空间改大一点?一脸懵。。
调优的基本流程 刚接触调优的新手面对200多个GC参数基本上都会一脸懵逼,然后随便调几个参数试试结果或者改几行代码试试,但是这样的操作基本上是徒劳的。GC调优和其他的其他的性能调优其实是同样的道理 ,只要按照一下的步骤操作,基本能保证我们调优的大方向不会错。
列出性能调优指标(State your performance goals) 执行测试(Run tests) 检查结果(Measure the results) 与目标进行对比(Compare the results with goals) 如果达不到指标,修改配置参数,然后继续测试(go back to running tests)
核心概念 第一步,我们需要做的事情是:制定明确的GC性能指标。对所有的性能监控和管理来看,有三个纬度是通用的:
Latency(延迟) Throughput(吞吐量) Capacity(系统容量)
Latency(延迟) GC的延迟率指标由一般的延迟需求决定。延迟指标的描述一般如下:
所有的交易必须在10秒内得到响应。
90%的订单付款操作必须在3秒内处理完成。
推荐商品必须在 100ms 内展示到用户面前。
面对这类性能指标时,需要保证在交易过程中,GC暂停时间不能占用太多的时间 ,否则满足不了指标,但是我们知道在GC过程中是必定会进行STW的,那么这里的“不能占用太多”的意思是需要视具体情况而定,还要考虑其他的因素,比如外部数据源的交互时间(round-trips),锁竞争(lock contention),以及其他的安全点等。
在CMS之前的垃圾收集器,垃圾收集工作周期都是需要全程暂停应用线程的,因此之前GC的延迟,在GC暂停期间就是一个几乎没有优化的空间的硬伤。
假设性能需求为:90% 的交易要在1000ms 以内完成,每次交易最长不能超过10s。根据经验,假设GC暂停时间比例不能超过10%,也就是90%的GC暂停必须在100ms内结束,也不能超过1000ms的GC暂停。为了简单期间,我们忽略在同一次交易过程中发生多次的GC的停顿可能性。下面是一段GC日志片段。
1 2015 ‐06 ‐04 T13 : 34 : 16.974 ‐0200 : 2.578 : [ Full GC ( Ergonomics ) [ PSYoungGen : 93677 K ‐> 70109 K ( 254976 K ) ] [ ParOldGen : 499597 K ‐> 511230 K ( 761856 K ) ] 593275 K ‐> 581339 K ( 1016832 K ) , [ Metaspace : 2936 K ‐> 2936 K ( 1056768 K ) ] , 0.0713174 secs ] [ Times : user = 0.21 sys = 0.02 , real = 0.07 secs ]
上面的这段日志表示一次Parallel GC暂停,发生在2015‐06‐04T13:34:16.974‐0200 ,对应着JVM启动后的第2.578秒。本次应用线程暂停了0.0713174秒。这次是一次 FullGC 暂停,花费的总时间210ms,但因为是多核CPU机器,所有最后重要的数字是应用线程被暂停的总时间real,这里使用的是并行GC,所以暂停的总时间是70ms,这里我们的性能要是90%的GC暂停必须在100ms内结束,这里的暂停时间是70ms,满足要求。
Throughput(吞吐量) 吞吐量和延迟指标有很大区别。当然两者都是根据一般吞吐量需求而得出的。一般吞吐量需求(Generic requirements for throughput)类似下面这样:
解决方案必须每天处理100万个订单。
解决方案必须支持1000个登录用户,同时在5~10秒内执行某个操作:A、B或C。
每周对所有客户进行统计,时间不超过6小时,时间窗口为每周日晚12点到次日6点之间。
可以看出,吞吐量需求不是针对单个操作的,而是给定的时间内,系统必须完成多少个操作 。和延迟需求类似,GC调优也需要去定GC行为所消耗的总时间。每个系统能接受的时间不同,一般来说,GC占用的总时间比不能超过 10%。
假设选在需求为:每分钟处理 1000 笔交易。同时,每分钟GC暂停的总时间不能超过6秒(即10%)。有了正式的需求,通过分析GC日志,我们可以得到下面这些信息。
1 2015 ‐06 ‐04 T13 : 34 : 16.974 ‐0200 : 2.578 : [ Full GC ( Ergonomics ) [ PSYoungGen : 93677 K ‐> 70109 K ( 254976 K ) ] [ ParOldGen : 499597 K ‐> 511230 K ( 761856 K ) ] 593275 K ‐> 581339 K ( 1016832 K ) , [ Metaspace : 2936 K ‐> 2936 K ( 1056768 K ) ] , 0.0713174 secs ] [ Times : user = 0.21 sys = 0.02 , real = 0.07 secs ]
此时我们对用户耗时(user)和系统耗时(sys)感兴趣而不关心实际耗时(real)。这里我们关心的时间为0.23s(user + sys = 0.21s + 0.02s),这段时间内,GC暂停会占用CPU资源。重要的是系统运行在多核心的机器上,转换到实际的停顿时间(stop-the-world) 为0.07131474秒。提取出这些有用的信息之后,剩下的就是要统计每分钟内GC暂停的总时间。看看是否满足需求。每分钟内暂停时间不超过6000毫秒(6秒)。
其实对与吞吐量的优化还是围绕着GC吞吐量公示来的,即:吞吐量 = 运行应用代码时间/(运行应用代码时间+ 运行垃圾收集时间)**。其实我们可以发现,只要缩短单位时间内垃圾收集时间暂停时间就能增加吞吐量,因此在调优吞吐量我们还是需要关心 单位时间内暂停的总时长**。
关于 GCTime 中的 user、sys、real。这个问题之前困扰了我很久很久,他们之间的关系是什么?为什么会 user + sys = real?
我之前是知道user、sys、real 分别代表 用户耗时、系统耗时、实际耗时。但是他们之间的关系看的不是很明白。难道单次GC的用户耗时还能比实际耗时还要久?这次梳理我又去重新找了资料理解这几个时间背后的意思。
user 进程执行用户态代码(核心之外)所有的时间。这是执行此进程此线程所使用的实际CPU时间。其他进程和此阻塞线程的时间并不包括在内。在是垃圾收集的情况下,表示GC线程执行所使用的CPU总时间。sys 进程在内核态消耗的 CPU 时间,即在内核执行系统调用或者等待系统事件所使用的 CPU 时间。real 程序从开始到结束所用的时钟时间。这个时间包括其他进程使用的时间片和进程阻塞的时间(比如等待I/O完成)。
user + sys 时间告诉我们,程序实际执行使用的CPU时间,这里是指所有的CPU ,因此有多个线程的话,这个时间会超过 real 所表示的时钟时间 。
通常情况下我们只需要参考real时间来进行优化,如果我们想通过增加线程或者增加CPU数量来减少GC停顿时间 ,我们可以参考user和sys。
Capacity(系统容量) 系统容量(Capacity)需求,是达成吞吐量和延迟指标的情况下,对硬件环境的额外约束。这类需求大多数都是源于计算资源或者预算方面的原因。例如:
系统必须能部署到小于512MB内存的Android设备上。
系统必须部署在配置不超过4核8GB的ECS上。
每个月云ECS的账单不超过10000元。
因此,在满足延迟和吞吐量需求的基础上必须考虑系统容量 。如果有无限的计算资源可以挥霍,那么任何延迟和吞吐量的指标都可以满足,但是现实是预算和其他约束限制了可用的资源。
没有资源的限制也就没有调优。
针对指标的简单调优示例 介绍完上面的三个指标,我们对下面的程序进行实际分析操作以达成GC指标。测试代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 public class Producer implements Runnable {private static ScheduledExecutorService executorService = Executors.newScheduledThreadPool(2 ); private Deque<byte []> deque ; private int objectSize; private int queueSize; public Producer (int objectSize, int ttl) this .deque = new ArrayDeque<byte []>();this .objectSize = objectSize;this .queueSize = ttl * 1000 ; public void run () for (int i = 0 ; i < 100 ; i++) { deque .add(new byte [objectSize]);if (deque .size () > queueSize) { deque .poll();public static void main (String [] args) throws InterruptedException new Producer(200 * 1024 * 1024 / 1000 , 5 ), 0 , 100 , TimeUnit.MILLISECONDS ); new Producer(50 * 1024 * 1024 / 1000 , 120 ), 0 , 100 , TimeUnit.MILLISECONDS); 10 ); executorService.shutdownNow();
这段代码每100ms提交两个作业(job),每个作业都模拟特定的生命周期:创建对象,然后在特定的时间释放,接着就不管了,由GC来自动回收占用的内存。我们通过下面的JVM参数打开GC日志信息,并通过加上JVM参数-Xloggc 来指定GC日志的存储位置。
1 -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCTimeStamps -Xloggc:gc.log
这样我们可以得到如下的一些日志输出信息:
1 2 3 4 5 2021 - 07 - 04 T17 : 03 : 12.320 - 0800 : 0.284 : [ GC ( Allocation Failure ) [ PSYoungGen : 65442 K -> 10721 K ( 76288 K ) ] 65442 K -> 63175 K ( 251392 K ) , 0.0429520 secs ] [ Times : user = 0.03 sys = 0.08 , real = 0.04 secs ] 2021 - 07 - 04 T17 : 03 : 12.518 - 0800 : 0.482 : [ GC ( Allocation Failure ) [ PSYoungGen : 76078 K -> 10710 K ( 141824 K ) ] 128531 K -> 128246 K ( 316928 K ) , 0.0607000 secs ] [ Times : user = 0.03 sys = 0.07 , real = 0.06 secs ] 2021 - 07 - 04 T17 : 03 : 12.579 - 0800 : 0.542 : [ Full GC ( Ergonomics ) [ PSYoungGen : 10710 K -> 0 K ( 141824 K ) ] [ ParOldGen : 117535 K -> 128105 K ( 275968 K ) ] 128246 K -> 128105 K ( 417792 K ) , [ Metaspace : 2729 K -> 2729 K ( 1056768 K ) ] , 0.0303548 secs ] [ Times : user = 0.10 sys = 0.01 , real = 0.03 secs ] 2021 - 07 - 04 T17 : 03 : 13.114 - 0800 : 1.077 : [ GC ( Allocation Failure ) [ PSYoungGen : 131072 K -> 10748 K ( 141824 K ) ] 259177 K -> 259140 K ( 417792 K ) , 0.1061217 secs ] [ Times : user = 0.06 sys = 0.11 , real = 0.11 secs ] ...
基于日志中的信息,我们可以通过三个优化目标来提升性能:
确保最坏情况下,GC暂停时间不超过预定阈值。
确保线程暂停的总时间不超过预定阈值。
在确保达到延迟和吞吐量的指标下,降低硬件配置以及成本。
为此我们使用三种不同配置,将代码运行10分钟,得到了三种不同的结果,汇总如下:
堆内存大小(Heap)
GC算法(GC Algorithm)
有效时间比(Useful work)
最长暂停时间(Longest pause)
-Xmx12g
-XX:+UseConcMarkSweepGC
89.8%
560ms
-Xmx12g
-XX:+UseParallelGC
91.5%
1104ms
-Xmx8g
-XX:UseConcMarkSweepGC
66.3%
1610ms
使用不同的GC算法和不同的内存配置,运行相同的代码,以测量GC暂停时间与延迟、吞吐量的关系。
⚠️为了尽可能简单,示例中只改变了很少的输入参数,此实验也灭有在不同的CPU数量或者不同的堆布局下进行测试
调优延迟指标(Tuning for Latancy) 假设我们有一个需求,每次作业必须在 1000ms 内处理完成。我们知道,实际的作业处理只需要100ms,简化后,两者相减我们就可以算出对GC暂停的延迟要求。现在需求变成:GC暂停时间不能超过900ms。这个问题就很容易找到答案,只要分析GC日志文件,并找出GC暂停中最大的那个暂停时间即可。
堆内存大小(Heap)
GC算法(GC Algorithm)
有效时间比(Useful work)
最长暂停时间(Longest pause)
-Xmx12g
-XX:+UseConcMarkSweepGC
89.8%
560ms
-Xmx12g
-XX:+UseParallelGC
91.5%
1104ms
-Xmx8g
-XX:UseConcMarkSweepGC
66.3%
1610ms
从上表中,其中我们可以看到有一个配置达到了要求,当堆内存大小为-Xmx12g -XX:+UseConcMarkSweepGC是最大的暂停时间为560ms,满足最大暂停时间小于900ms的目标,如果没有其他的关于吞吐量和系统容量的要求的话,目标达成调优结束。其运行配置参数为:
1 -Xmx12g -XX:+UseConcMarkSweepGC
吞吐量调优(Tuning for Throughout) 假定吞吐量指标为:每小时完成1300万次操作处理。同样是上面的配置,其中有一种配置满足了需求:
堆内存大小(Heap)
GC算法(GC Algorithm)
有效时间比(Useful work)
最长暂停时间(Longest pause)
-Xmx12g
-XX:+UseConcMarkSweepGC
89.8%
560ms
-Xmx12g
-XX:+UseParallelGC
91.5% 1104ms
-Xmx8g
-XX:UseConcMarkSweepGC
66.3%
1610ms
从上面的表格的数据不难得出,这里-Xmx12g -XX:+UseParallelGC是唯一有效的解。这里的GC占用的8.5%的时间,剩下91.5%都是有效的计算时间。为了简单起见,我们忽略示例中的其他安全点。现在需要考虑:
每个CPU核心处理一次作业需要耗时100ms。
因此,一分钟内每个核心可以执行60000次操作(每个job完成100次操作)。
一小时内,一个核心可以执行360万次。
有四个CPU内核,则每小时可以执行:4 * 3.6M = 1440万次操作。
理论上,通过简单的计算就可以得出结论,每小时可以执行的操作数为:14.4M * 91.5% = 13176000次,满足需求。值得一提的是,假若还要满足延迟指标,那就有问题了,最坏的情况下,GC暂停时间为1104ms,最大延迟时间是前一种配置的两倍。
1 -Xmx12g -XX:+UseParallelGC
调优系统容量(Tuning for Capacity) 假设需要将软件部署到服务器上,配置为4核10G。这样的话,系统容量的要求就变成,最大的堆内存空间不能超过8G。有了这个需求,我们的三套配置只有最后一个满足条件。
堆内存大小(Heap)
GC算法(GC Algorithm)
有效时间比(Useful work)
最长暂停时间(Longest pause)
-Xmx12g
-XX:+UseConcMarkSweepGC
89.8%
560ms
-Xmx12g
-XX:+UseParallelGC
91.5%
1104ms
-Xmx8g -XX:UseConcMarkSweepGC
66.3%
1610ms
因此在这个需求下的运行配置
1 -Xmx8g -XX:+UseConcMarkSweepGC
日志分析工具 之前我们梳理过一些监控诊断工具,其中有很多工具都可以很好的监控GC,其中命令行工具 jstat -gc,jvisulvm,jmc都是可以很有效的监控堆空间使用以及GC工作情况。这里就详细介绍了,如果有不太记得了的朋友,可以回去看看😏。其中最主要用于分析GC的GC信息还是GC日志,日志中包含了GC最全面的描述,就是GC事实上的标准,可以作为GC性能评估的最真实数据来源。GC日志一般输出到文件之中,是纯text格式的,当然也可以打印到控制台。有多个可以控制GC日志的JVM参数,例如可以打印每次GC的持续时间,以及程序暂停时间(-XX:+PrintGCApplicationStoppedTime),还有GC清理了多少引用类型(-XX:+PrintReferenceGC)。
其中最基础的要打印出GC日志,需要在启动参数中指定以下参数(将所有GC事件打印到日志文件中,输出每次GC的日期和时间戳。不同GC算法输出的内容略有不同):
1 ‐XX:+PrintGCTimeStamps ‐XX:+PrintGCDateStamps ‐XX:+PrintGCDetails ‐Xloggc:<filename >
下面是一段GC的日志信息,其中记录了5次GC信息,其中包括了1次youngGC,还包括了4次FullGC。
1 2 3 4 5 2021 - 07 - 04 T17 : 03 : 30.892 - 0800 : 18.775 : [ GC ( Allocation Failure ) [ PSYoungGen : 920064 K -> 189402 K ( 1143808 K ) ] 2723073 K -> 2722965 K ( 3912704 K ) , 0.3732643 secs ] [ Times : user = 0.52 sys = 0.37 , real = 0.37 secs ] 2021 - 07 - 04 T17 : 03 : 31.266 - 0800 : 19.148 : [ Full GC ( Ergonomics ) [ PSYoungGen : 189402 K -> 0 K ( 1143808 K ) ] [ ParOldGen : 2533562 K -> 1984964 K ( 2796544 K ) ] 2722965 K -> 1984964 K ( 3940352 K ) , [ Metaspace : 2764 K -> 2764 K ( 1056768 K ) ] , 0.1733963 secs ] [ Times : user = 1.04 sys = 0.01 , real = 0.17 secs ] 2021 - 07 - 04 T17 : 03 : 34.496 - 0800 : 22.378 : [ Full GC ( Ergonomics ) [ PSYoungGen : 954368 K -> 0 K ( 1143808 K ) ] [ ParOldGen : 1984964 K -> 2171912 K ( 2796544 K ) ] 2939332 K -> 2171912 K ( 3940352 K ) , [ Metaspace : 2777 K -> 2777 K ( 1056768 K ) ] , 0.2171111 secs ] [ Times : user = 1.14 sys = 0.02 , real = 0.22 secs ] 2021 - 07 - 04 T17 : 03 : 38.196 - 0800 : 26.078 : [ Full GC ( Ergonomics ) [ PSYoungGen : 954368 K -> 0 K ( 1143808 K ) ] [ ParOldGen : 2171912 K -> 2361421 K ( 2796544 K ) ] 3126280 K -> 2361421 K ( 3940352 K ) , [ Metaspace : 2780 K -> 2780 K ( 1056768 K ) ] , 0.2804937 secs ] [ Times : user = 1.44 sys = 0.03 , real = 0.28 secs ] 2021 - 07 - 04 T17 : 03 : 41.895 - 0800 : 29.777 : [ Full GC ( Ergonomics ) [ PSYoungGen : 954368 K -> 0 K ( 1143808 K ) ] [ ParOldGen : 2361421 K -> 2550111 K ( 2796544 K ) ] 3315789 K -> 2550111 K ( 3940352 K ) , [ Metaspace : 2782 K -> 2782 K ( 1056768 K ) ] , 0.2061000 secs ] [ Times : user = 1.25 sys = 0.03 , real = 0.21 secs ]
在上面的日志信息中记录了如下的信息:
这一段日志截取自JVM后启动的18秒到30秒的区间。
young区域的空间大小是 1143808K 即 1117MB,老年代空间 2796544K 即 2731MB,这个堆空间大小3940352K 即 3848MB,Metaspace空间大小1032MB。
在这一段GC日志中,应用总共运行了 11.0002s,期间发生了4次GC(不算最后一次GC)其中3次FullGC和一次YoungGC,其中GC总暂停时间为1.25s,占总运行时间的~=8.8%。
在第一次youngGC之后,后续的GC全部为FullGC,并且在每次FullGC,整个堆空间的占用依旧呈现上升趋势,可以看出内存空间并不能及时的释放。
通过对这些日志的简单分析,我们基本可以得出,目前JVM的GC是病态的,JVM频繁地进行FullGC,并且FullGC后,堆内存仍然呈上升的趋势。可以预见的是当增长的内存空间超过堆空间大小,应用将会出现OOM或持续GC无法正常工作的情况。
当然我们还可以从GC日志中得到更多的信息,比如在某个时间段内内存的分配速率和垃圾收集速率,在每次垃圾youngGC后对象的晋升速率等等。但是如果一般系统会产生大量的GC日志,纯靠人工很难进行完全地阅读和分析。
这个时候我们就要合理的利用我们的GC日志分析工具来帮助我们充分分析诊断GC,这里我们主要介绍两个工具在GC调优过程中的使用,一个是GCViewer,另外一个是 GCEasy。
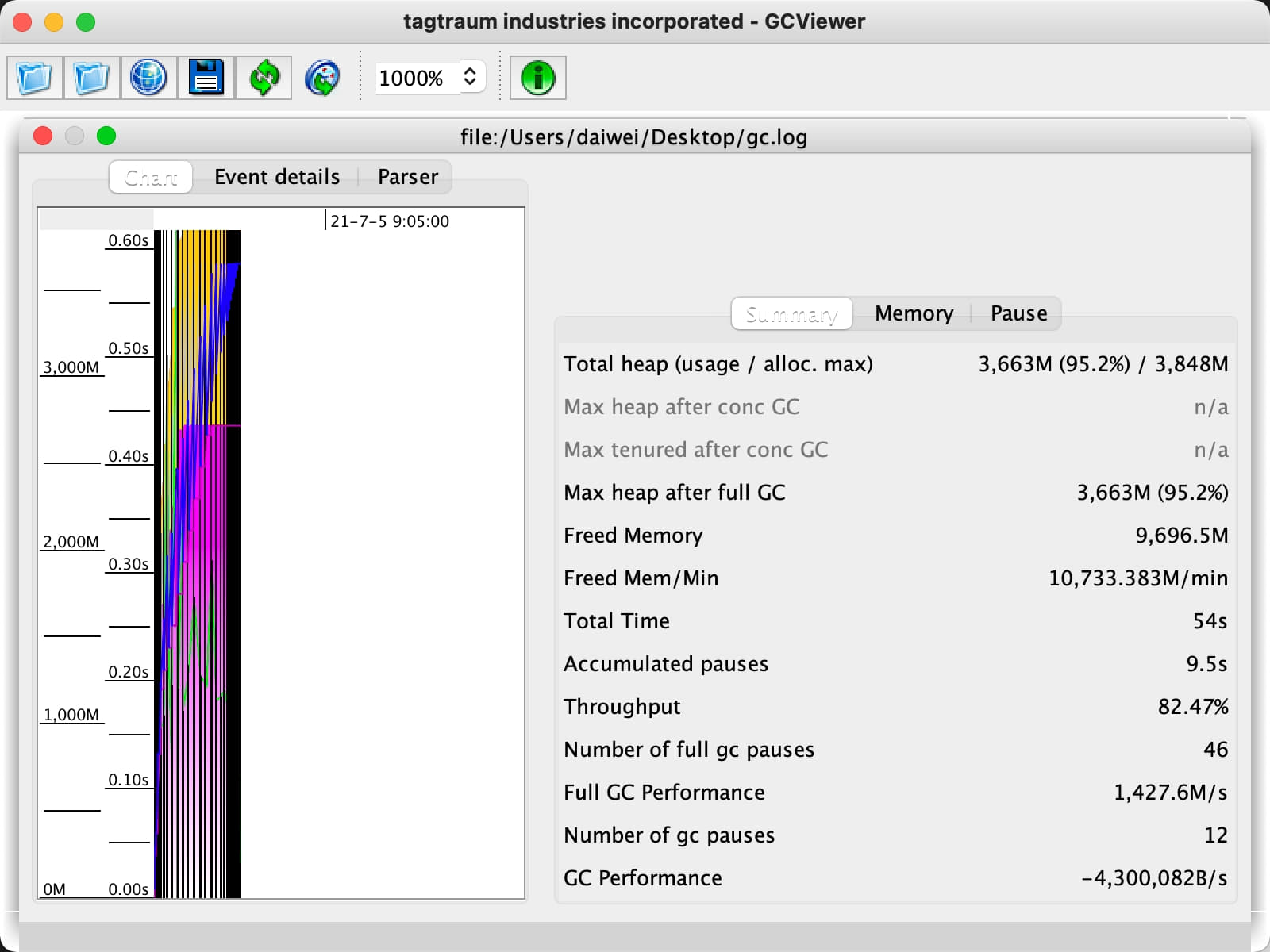
GCViewer GCViewer 是一个开源工具的GC日志分析工具。项目在 GitHub 主页各项指标进行了完整的描述。下面我们介绍一些常用指标。第一步获取GC日志文件,并且使用以下命令打开 GCViewer,并且得到下面的界面。
1 java -jar gcviewer-1 .36 .jar gc.log
如果不想打开界面,我们也可以使用下面的命令将GC数据导出到 summary.cvs 和 chart.png 中
1 java -jar gcviewer-1.36 .jar gc.log summary .csv chart.png
我们一起来简单看下分析下GCViewer输出的数据,我们先从左侧的第一个tab页图表(Chart)开始。GCViewer使用折线向我们展示了内存空间以及垃圾收集器的工作情况。其中黑色的线代表的是FullGC,深紫色的线表示堆空间的使用,绿色的线表示GC时间。图中两种颜色对应的区域,其中黄色的代表年轻代,紫色代表老年代。
第二个tab页面是事件详情(Event details)其中记录了GC暂停事件(GC pauses)、FullGC暂停事件(Full gc pauses)和并发GC其中在GC暂停事件中,我们能看到这些GC事件的名称(name)、次数(n)、最小值(min)、最大值(max)、平均值(avg)、标准差(stddev)、总时间(sum(s))、分项总时间占比(sum(%))。我们可以看到GC暂停(GC pauses)记录的是YoungGC的暂停时间,而FullGC暂停(Full GC pauses)记录了两类暂停,一类是分配失败的FullGC(Allocation Failure),另一类是自适应(Ergonomics)产生的FullGC。其中我们不难发现绝大多数大部分的FullGC是由自适应调整带来的FullGC。我们测试的是 ParallelGC ,GC时会全程暂停应用线程,因此没有并发GC的数据。
第二个tab页是内存有关信息(Memory),这里包括各个分代内存的使用情况、GC后的内存释放信息和对西那个的晋升速率的信息,可以帮助我们有效的分析堆空间中对象的存活与回收情况。
最后一个tab页是暂停有关信息(pause)从总暂停、FullGC暂停、GC暂停这三个纬度统计了GC的最大、最小和平均暂停时间、GC间隔时间的数据,这些数据可以帮助我们全面分析GC的暂停情况。
以上就是GCViewer对一次GC日志的分析结果,GCViewer通过GC日志对GC的内存和暂停进行了充分的分析,数据分析地非常全面。但如果要说缺点的话,GCViewer的UI设计还有很大的提升空间。
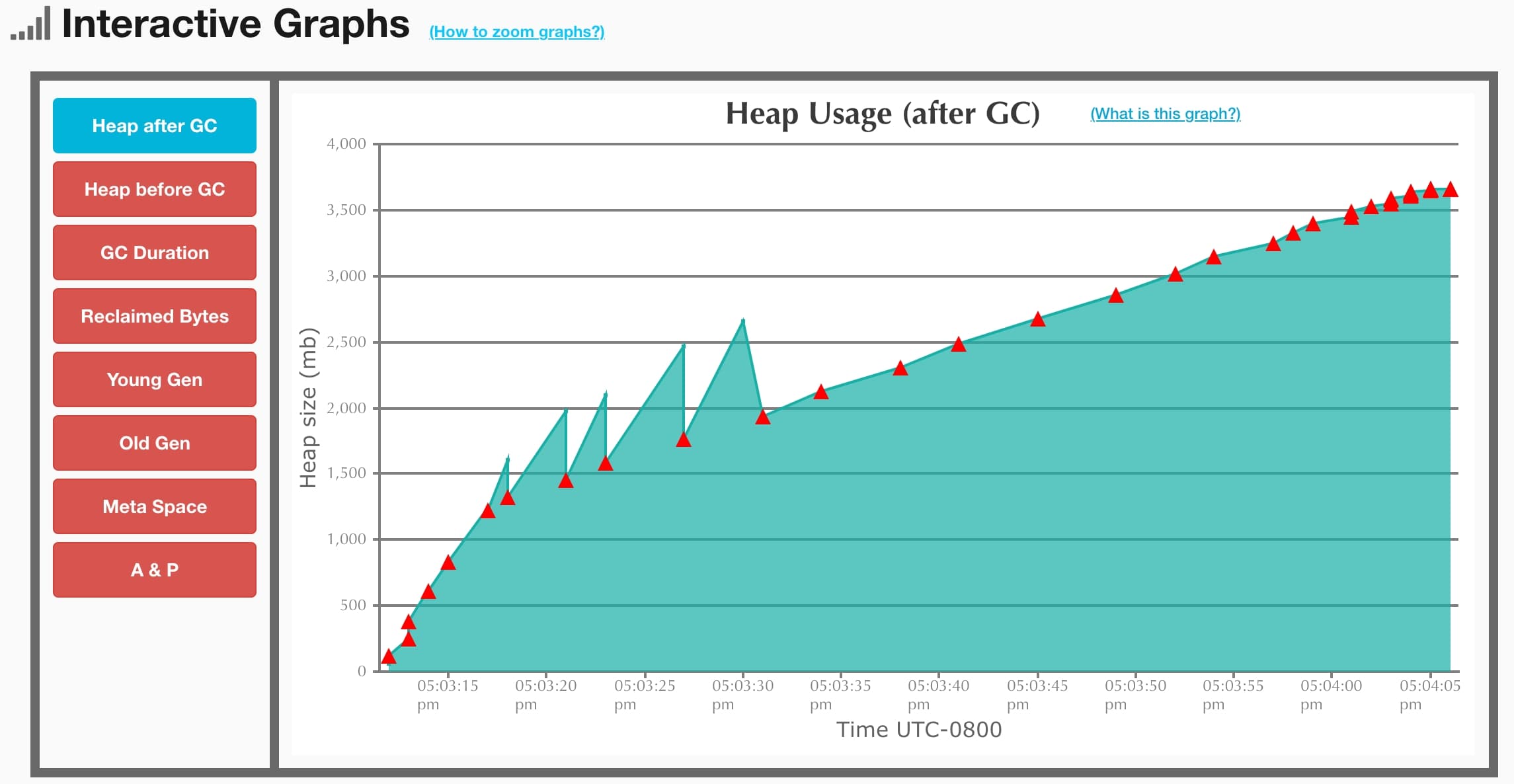
GCEasy GCEasy在前面的文章中我们做过简单的介绍,今天介绍GC的分析结果。通过GCEasy输出的图表数据,帮助大家快速有效的分析GC日志。第一个图表是JVM的内存概览图,左侧是图表包括分配内存量,和内存最大值,右侧是数据的柱状图。
第二个图表是关键性能指标(Key Performance Indicators),其中主要记录的指标是吞吐量和GC暂停的图表数据。
第三张图是交互图表(Interactive Graphs),其中Heap after GC表示GC后的堆空间大小,Heap before GC表示GC前的堆空间大小,
GC Duration是GC的持续时间,Reclaimed Bytes表示GC后回收的字节大小,Young Gen表示young区的内存使用情况,同理Old Gen表示老年代的内存使用情况,Meta Space 表示Meta区的内存使用情况最后一个A & P表示对象从新生代晋升到老年代的晋升速率。
第四张图表是GC的统计数据(GC Statistics),按照各个不同的纬度统计GC的数据,可以帮助我们从各个角度详细的分析GC。
最后的两张图是对象统计(Object Stats)和 GC产生原因(GC Causes)分析,其中对象统计计算了对象创建数量和对象晋升的数据。而GC产生原因分析造成GC的原因以及相关的一些GC产生时的一些数据统计。
以上就是GCEasy对“普通”用户上传的GC日志进行分析的结果,如果想要获得更多的数据可以进行充值,但是这么多纬度和这么数据分析足以让我们完成GC问题定位和GC调优目标达成判定。相较于GCViewer,GCEasy的图表更加丰富,结果展示更加直观,并且不用额外下载软件。如果遇到此类需求,我更倾向使用GCEasy🙈。
GC调优实战 这一小节我们介绍导致性能问题的典型情况,这些示例都是来自于生产环境,为演示做了一定长度的精简。
Allocation Rate 翻译过来就是分配速率,而不是分配率;因为不是百分比,而是单位时间内分配的量。
Promotion Rate 翻译为 提成速率,即从新生代提升到老年代的速率。
高分配速率(High Allocation Rate) 分配速率(Allocation rate)表示单位时间内分配的内存量。通常使用MB/sec作为单位,也可以使用PB/year 等。分配率过高就会严重影响程序的性能,在JVM中会导致巨大的GC开销。
如何测量分配速率 在测试分配速率之前,我们需要设置JVM参数:-XX:+PrintGCDetails -XX:+PrintGCTimeStamps,通过GC日志来计算分配速率,GC日志如下所示:
1 2 3 4 5 6 7 8 9 0.291 : [ GC ( Allocation Failure ) [ PSYoungGen : 33280 K ‐> 5088 K ( 38400 K ) ] 33280 K ‐> 24360 K ( 125952 K ) , 0.0365286 secs ] [ Times : user = 0.11 sys = 0.02 , real = 0.04 secs ] 0.446 : [ GC ( Allocation Failure ) [ PSYoungGen : 38368 K ‐> 5120 K ( 71680 K ) ] 57640 K ‐> 46240 K ( 159232 K ) , 0.0456796 secs ] [ Times : user = 0.15 sys = 0.02 , real = 0.04 secs ] 0.829 : [ GC ( Allocation Failure ) [ PSYoungGen : 71680 K ‐> 5120 K ( 71680 K ) ] 112800 K ‐> 81912 K ( 159232 K ) , 0.0861795 secs ] [ Times : user = 0.23 sys = 0.03 , real = 0.09 secs ]
计算上一次垃圾收集之后,与下一次GC开始之前的年轻代使用量,两者的差值除以时间,就是分配速率。痛殴上面的日志,可以计算出以下的信息:
JVM启动之后291ms,共创建了33280KB的对象。第一次 Minor GC(小型GC)完成后,年轻代中还有5088KB的对象存活。
在启动之后446ms,年轻代的使用量增加到38368KB,触发第二次GC,触发第二次GC,完成后年轻代的使用量减少到5129KB。
在启动之后829ms,年轻代的使用量为71680KB,GC后变为5120KB。
通过使用年轻代的使用量我们可以计算分配速率(Allocation druing/ time),如下表所示:
Event
TIme
Young before
Young after
Allocation during
Allocation rate
1st GC
291ms
33280KB
5088KB
33280KB
144MB/sec
2nd GC
446ms
38368KB
5120KB
33280KB
215MB/sec
3rd GC
829ms
71680KB
5120KB
66560KB
173MB/sec
Total
829ms
N/A
N/A
133120KB
161MB/sec
通过这些信息可以知道,在测量期间,该程序的内存分配速率为161MB/sec。
分配速率的意义 分配速率的的变化,会增加或降低GC暂停的频率,从而影响吞吐量。但只有年轻代的minor GC受分配速率的影响,老年代GC的频率和持续时间不受分配速率(allocation rate)的直接影响,而收到提升速率(promotion rate)的影响。
现在我们只关心 Minor GC的暂停,查看年轻代的3个内存池。因为对象在Eden区分配。所以我们一起来看 Eden 区的大小和分配速率的关系,看看增加 Eden 区的容量,能不能减少Minor GC 暂停次数,从而使程序能够维持更高的分配速率。进过我们的实验,通过参数 -XX:NewSize、-XX:MaxNewSize以及-XX:SurvivorRatio 设置不同的Eden空间,运行同一程序时,可以发现:
Eden 空间为100MB 时,分配速率低于100MB/sec。
将 Eden 区增加为1G,分配速率也随之增长,大约等于200MB/sec。
为什么会这样?因为减少GC暂停,就等价于减少了任务线的暂停,就可以更多的工作了 ,也就可以创建更多的对象,所以对同一应用来说,分配速率越高越好。通过这个结论我们可以得出“** Eden区越大越好**” 这个结论前,我们注意到,分配速率可能会也可能不会影响程序的实际吞吐量。吞吐量和分配速率有一定关系,因为分配速率会影响MinorGC暂停,但对于总体吞吐量的影响,还要考虑MajorGC暂停,而且吞吐量的单位不是MB/s,而是系统所处理的业务量。
高分配率对JVM的影响及解决方案 首先,我们应该检查程序的吞吐量是否降低,如果创建了过多的临时对象,minorGC的次数将会增加。如果并发较大,则GC可能会严重影响吞吐量。遇到这种情况时,MinorGC会非常频繁,GC日志将会像下面这样,JVM的启动参数为-XX+PringGCDetails -XX:PringGCTimeStamps -Xmx32m。
1 2 3 4 5 6 7 8 9 2.808 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003076 secs ] 2.819 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003079 secs ] 2.830 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0002968 secs ] 2.842 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003374 secs ] 2.853 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0004672 secs ] 2.864 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003371 secs ] 2.875 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003214 secs ] 2.886 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003374 secs ] 2.896 : [ GC ( Allocation Failure ) [ PSYoungGen : 9760 K ‐> 32 K ( 10240 K ) ] , 0.0003588 secs ]
很显然minGC 的频率太高了,这说明创建了大量的对象。另外年轻在GC之后的使用量又很低,也没有FullGC发生,种种迹象表明,GC对吞吐量造成了严重的影响。那么我们要如何处理这些问题呢?其实在某些情况下,只要增加年轻代的大小,即可降低分配速率过高所造成的影响 ,增加年轻代并不会降低分配速率,但是会减少GC的频率,如果每次GC剩余的对象很少,GC的持续时间也不会明显的增长。增加年轻代是开源的方式解决,我们还可以节流。我们可以在代码中尽量使用基础类型代替包装类型,从而减少对象的创建。
提升速率(promotion rate),用于衡量单位时间内从年轻代提升到老年代的数据量 ,一般用MB/sec作为单位和分配速率类似。JVM会将长时间存活的对象从年轻代提升到老年代。根据分代假设,可能存在一种情况,老年代中不仅有存活时间长的对象,也可能存在存活时间短的对象。因此过早提升即对象存活时间还不够长的时候就被提升到老年代。 majorGC 不是为频繁回收而设计的,但 majorGC现在也要清理这些生命短暂的对象,就会导致GC暂停时间过长,这会严重影响系统的吞吐量** 。**
如何测量提升速率 可以指定JVM参数-XX:+PrintGCTimeStamps,通过GC日志来测量提升速率,JVM记录的GC暂停信息如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 2.176 : [ Full GC ( Ergonomics ) [ PSYoungGen : 9216 K ‐> 0 K ( 10752 K ) ] [ ParOldGen : 10020 K ‐> 9042 K ( 12288 K ) ] 19236 K ‐> 9042 K ( 23040 K ) , 0.0036840 secs ] 2.394 : [ Full GC ( Ergonomics ) [ PSYoungGen : 9216 K ‐> 0 K ( 10752 K ) ] [ ParOldGen : 9042 K ‐> 8064 K ( 12288 K ) ] 18258 K ‐> 8064 K ( 23040 K ) , 0.0032855 secs ] 2.611 : [ Full GC ( Ergonomics ) [ PSYoungGen : 9216 K ‐> 0 K ( 10752 K ) ] [ ParOldGen : 8064 K ‐> 7085 K ( 12288 K ) ] 17280 K ‐> 7085 K ( 23040 K ) , 0.0031675 secs ] 2.817 : [ Full GC ( Ergonomics ) [ PSYoungGen : 9216 K ‐> 0 K ( 10752 K ) ] [ ParOldGen : 7085 K ‐> 6107 K ( 12288 K ) ] 16301 K ‐> 6107 K ( 23040 K ) , 0.0030652 secs ]
从上面的日志可以得知:GC之前和之后的年轻代使用量以及堆内存使用量。这样就可以通过差值算出老年代的使用量,GC日志中的信息可以表述为:
Event
TIme
Young descreased
Total descreased
Promoted
Promotion rate
事件
耗时
年轻减少
整个堆内存减少
提升量
提升速率
1st GC
291ms
28192K
8920K
19272K
66.2MB/sec
2nd GC
446ms
33248K
11400K
21848K
140.95MB/sec
3rd GC
829ms
66560K
30888K
35672K
93.14MB/sec
Total
829ms
76792K
92.63MB/sec
乍一看似乎不是过早提升的问题。事实上,在每次GC之后老年代的使用率似乎在减少。但反过来想,要是没有对象提升或提升率很小,也就不会看到那么多的FullGC了。简单解释一下这里的GC行为:有很多对象提升到老年代,同时老年代中也有很多对象被回收了,这就是造成了老年代使用量减少的假性,但事实是大量的对象不断地被提升到老年代,并触发 fullGC。
提升速率的意义 和分配速率一样,提升速率也会影响GC暂停的频率。但是分配速率主要影响 MinorGC,而提升速率则直接影响 Major GC的频率。有大量的对象提升,自然很快将老年代塞满,老年代填充的越快,则Major GC事件的频率也就越高。
此前我们介绍过,fullGC 通常需要更多的时间,因为需要处理更多的对象,还需要执行碎片整理等额外的复杂过程。通常过早提升的症状表现为以下的形式:
短时间内频繁地执行FullGC。 每次FullGC后老年代的使用率都非常低,都在10%~20%或以下。 提升速率接近于分配速率。
解决方案 简单来说,要解决这类问题,需要让年轻代存放得下暂存的数据。有两种简单的方法:
增加年轻代的大小。 设置JVM启动参数,类似这样:-Xmx64m -XX:NewSize=32m,程序在执行时,Full GC 的次数自然会减少很多,只会 minorGC 的持续时间产生影响:
1 2 3 4 2.251 : [ GC ( Allocation Failure ) [ PSYoungGen : 28672 K ‐> 3872 K ( 28672 K ) ] 37126 K ‐> 12358 K ( 61440 K ) , 0.0008543 secs ] 2.776 : [ GC ( Allocation Failure ) [ PSYoungGen : 28448 K ‐> 4096 K ( 28672 K ) ] 36934 K ‐> 16974 K ( 61440 K ) , 0.0033022 secs ]
减少每次批处理的数量 。也能得到类似的结果,至于选用那个方案,要根据业务需求决定。在某些情况下,业务逻辑不允许减少批处理的数量,那就只能增加堆内存,或者重新指定年轻代的大小。
如果都不可行,就只能优化数据结构,减少内存消耗。但总体目标依然是一致的,让临时数据能够在年轻代存放的下。
能在年轻代就尽量不要提升到老年代,从而避免过早提升。
Weak,Soft 及 Phantom 引用 另一类影响GC的问题是程序中中的non-strong引用。虽然这类引用在很多情况下可以避免出现OutOfMemoryError,但过量使用也会对GC造成严重的影响,反而降低系统性能。
弱引用的缺点 首先,弱引用(weak reference) 是可以被GC强制回收的。当垃圾收集器发现一个弱可达对象(weakly reachable 即指向该对象的引用只剩下弱引用) 时,就会将其置入相应的ReferenceQueue中,变成可终结的对西那个,之后可能遍历这个 reference queue,并执行相应的清理。典型的示例是清除缓存中不再引用的KEY。当然,在这个时候,我们还可以将该对象赋值给新的强引用,在最后终结和回收前,GC会在此确认该对象是否可以安全回收。因此,弱引用对象的回收过程是横跨多个GC周期的。实际上弱引用使用的很多,大部分缓存框架(caching solution) 都是基于弱引用实现的 ,所以虽然业务代码中没有直接使用弱引用,但是程序中依然大量存在。其次,软引用(soft reference)比弱引用更难被垃圾收集器回收,回收软引用没有确切的时间点,由JVM自己决定,一般只会在即将耗尽可用内存时,才会回收软引用,以作最后手段 。这意味着,可能会有更频繁的 fullGC,暂停时间也比预期更长,因为老年代中的存活对象会很多。最后,使用虚引用(phantom reference)时,必须手动进行内存管理,以标识这些对象是否可以安全地回收 ,表面上看起来很正常,但实际上并不是。javadoc 中写到:
In order to ensure that a reclaimable object remains so, the referent of a phantom reference may not be
retrieved: The get method of a phantom reference always returns null. (为了防止可回收对象的残留,虚引用对象不应该被获取phantom reference 的 get 方法返回值永远是null)。
令人惊讶的是,很多开发这更容易忽略下面一段内容(这才是重点):
Unlike soft and weak references, phantom references are not automatically cleared by the garbage collector as they are enqueued. An object that is reachable via phantom references will remain so until all such references are cleared or themselves become unreachable.(与软引用和弱引用不同,虚引用不会被被GC自动清除,因为他们被存放在队列中,通过虚引用可达对象会继续存在内从中,直到调此引用的 clear 方法,或者引用自身变为不可达)。
也就是说,我们必须手动调用 clear() 来清除虚引用,否则可能造成OutOfMemeoryError 而导致JVM挂掉 ,使用虚引用的理由是,对于用编程手段来跟踪某个对象何时变为不可达对象,这是唯一的常规手段。和软引用/弱引用不同的是,我们不能复活虚可达(phantom-reachable)对象 。
使用非强引用的影响 建议使用JVM参数 -XX:+PrintReferenceGC 来看看各种引用对GC的影响,如果将此参数用于启动,将会看到:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 2.173 : [ Full GC ( Ergonomics ) 2.234 : [ SoftReference , 0 refs , 0.0000151 secs ] 2.234 : [ WeakReference , 2648 refs , 0.0001714 secs ] 2.234 : [ FinalReference , 1 refs , 0.0000037 secs ] 2.234 : [ PhantomReference , 0 refs , 0 refs , 0.0000039 secs ] 2.234 : [ JNI Weak Reference , 0.0000027 secs ] [ PSYoungGen : 9216 K ‐> 8676 K ( 10752 K ) ] [ ParOldGen : 12115 K ‐> 12115 K ( 12288 K ) ] 21331 K ‐> 20792 K ( 23040 K ) , [ Metaspace : 3725 K ‐> 3725 K ( 1056768 K ) ] , 0.0766685 secs ] [ Times : user = 0.49 sys = 0.01 , real = 0.08 secs ] 2.250 : [ Full GC ( Ergonomics ) 2.307 : [ SoftReference , 0 refs , 0.0000173 secs ] 2.307 : [ WeakReference , 2298 refs , 0.0001535 secs ] 2.307 : [ FinalReference , 3 refs , 0.0000043 secs ] 2.307 : [ PhantomReference , 0 refs , 0 refs , 0.0000042 secs ] 2.307 : [ JNI Weak Reference , 0.0000029 secs ] [ PSYoungGen : 9215 K ‐> 8747 K ( 10752 K ) ] [ ParOldGen : 12115 K ‐> 12115 K ( 12288 K ) ] 21331 K ‐> 20863 K ( 23040 K ) , [ Metaspace : 3725 K ‐> 3725 K ( 1056768 K ) ] , 0.0734832 secs ] [ Times : user = 0.52 sys = 0.01 , real = 0.07 secs ] 2.323 : [ Full GC ( Ergonomics ) 2.383 : [ SoftReference , 0 refs , 0.0000161 secs ] 2.383 : [ WeakReference , 1981 refs , 0.0001292 secs ] 2.383 : [ FinalReference , 16 refs , 0.0000049 secs ] 2.383 : [ PhantomReference , 0 refs , 0 refs , 0.0000040 secs ] 2.383 : [ JNI Weak Reference , 0.0000027 secs ] [ PSYoungGen : 9216 K ‐> 8809 K ( 10752 K ) ] [ ParOldGen : 12115 K ‐> 12115 K ( 12288 K ) ] 21331 K ‐> 20925 K ( 23040 K ) , [ Metaspace : 3725 K ‐> 3725 K ( 1056768 K ) ] , 0.0738414 secs ] [ Times : user = 0.52 sys = 0.01 , real = 0.08 secs ]
只有确认了GC对应的吞吐量和延迟造成影响之后,才应该花心思来分析这些信息,审查这部分日志,通常情况下,每次GC清理的引用数据都是很少的,发部分情况下为0,如果GC花了较多的时间来清理这类引用,或者清理了很多的此类引用,就需要进一步观察分析了。
解决方案 如果程序确实碰到了mis-, ab- 问题或者滥用 week,soft,phantom引用,一般都要修改程序的实现逻辑。每个系统不一样,因此很难提供通用的知道建议,但是有一些通用的办法:
弱引用(week reference) 如果某个内存池的使用量增大,造成了性能问题,那么增加内存池的大小(可能也要增加堆内存的最大容量)。如示例中可以看到,增加堆内存大小,以及年轻代的大小,可以减轻症状。软引用(soft reference) 如果确定问题的根源是软引用,唯一的解决办法是修改程序源码,改变内部实现逻辑。虚引用(Phantom reference) 请确保在程序中调用了虚引用的clear方法。编程中很容易忽略某些虚引用,或者清理的速度跟不上生产的速度,又或者清楚引用队列的线程挂了,就会对GC造成很大压力,最终引起OutOfMemeoryError。
巨无霸对象的分配(Humongous Allocation) 如果使用G1垃圾收集算法;会产生一种巨无霸对象引起的GC性能问题。
说明 在G1中,巨无霸对象是指所占空间超过一个小堆区(region) 50% 的对象。
频繁创建巨无霸对象,无疑会造成GC的性能问题,我们先看看G1的处理方式:
如果 region 中含有巨无霸对象,则巨无霸对象后面的空间将不会进行分配。如果所有巨无霸对象都超过某个比例,则未使用空间就会引发内存碎片问题。
G1 没有对巨无霸对象进行优化。这在JDK8以前是一个特别棘手的问题——在Java1.8u4.0之前的版本中,巨无霸对象所在region的回收只能在fullGC中进行。最新版本的Hotspot JVM,在marking 阶段之后的 cleanup 阶段中释放巨无霸区间,所以这个问题在新版本JVM中的影响已大大降低。
如果存在巨无霸对象分配问题会输出如下日志:
1 2 3 4 5 6 7 8 9 10 11 12 13 0.106: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation , reason: occupancy higher than threshold , occupancy: 60817408 bytes , allocation request: 1048592 bytes , threshold: 60397965 bytes (45.00 %) , source: concurrent humongous allocation ] 0.106: [G1Ergonomics (Concurrent Cycles) request concurrent cycle initiation , reason: requested by GC cause , GC cause: G1 Humongous Allocation ] 0.106: [G1Ergonomics (Concurrent Cycles) initiate concurrent cycle , reason: concurrent cycle initiation requested ] 0.106: [GC pause (G1 Humongous Allocation) (young) (initial‐mark) 0.106: [G1Ergonomics (CSet Construction) start choosing CSet , _pending_cards: 0 , predicted base time: 10.00 ms , remaining time: 190.00 ms , target pause time: 200.00 ms ]
这样的日志表明程序中确实创建了巨无霸对象,可以看到G1 Humongous Allocation 是GC暂停的原因。再看前面一点的allocation request: 1048592 bytes,可以发现程序试图分配一个1048592 字节的对象,这要比巨无霸区域(2MB)的50%多出16字节。第一中解决方式是修改 region size,以使得大多数的对象大小不超过50%,也就不进行巨无霸对象区域的分配。 region 的默认大小在启动时根据堆内存的大小算出。但也可以指定参数来覆盖默认设置,-XX:G1HeapRegionSize=XX。指定region size必须在1~32MB之间,还必须是2的幂大小,所以region size 只能是:1m,2m,4m,8m,16m,32m。 这种方式也有副作用,增加region 的大小也就变相减少了region 的数量,所以需要谨慎使用 。更好的方式是,如果可以的话在程序中限制对象大小 。避免大对象问题的出现。
总结 这一小节我们总结梳理了JVM目前主要使用中的GC的日志分析解读和GC调优,其中我们分析了SerialGC、ParallelGC、CMS 和 G1的日志,通过这段日志信息的解读为后面的GC调优打下基础。第二个部分我们介绍了GC调优。GC调优分为以下几步:列出性能调优指标、执行测试、检查结果、与目标进行对比、如果达不到指标,修改指标,调整参数继续测试。接下来我们介绍了几个核心参数概念:Latency、Throughput、Capacity。
我们可以针对这几个参数进行调优。当然手动人工的去分析一行行GC日志,效率必然很低也很容易漏掉一些参数,我们介绍了可视化GC工具——GCViewer 和 GCEasy。最后我们分析了线上的几种常见的GC问题的日志分析和解决方案。
学习资料