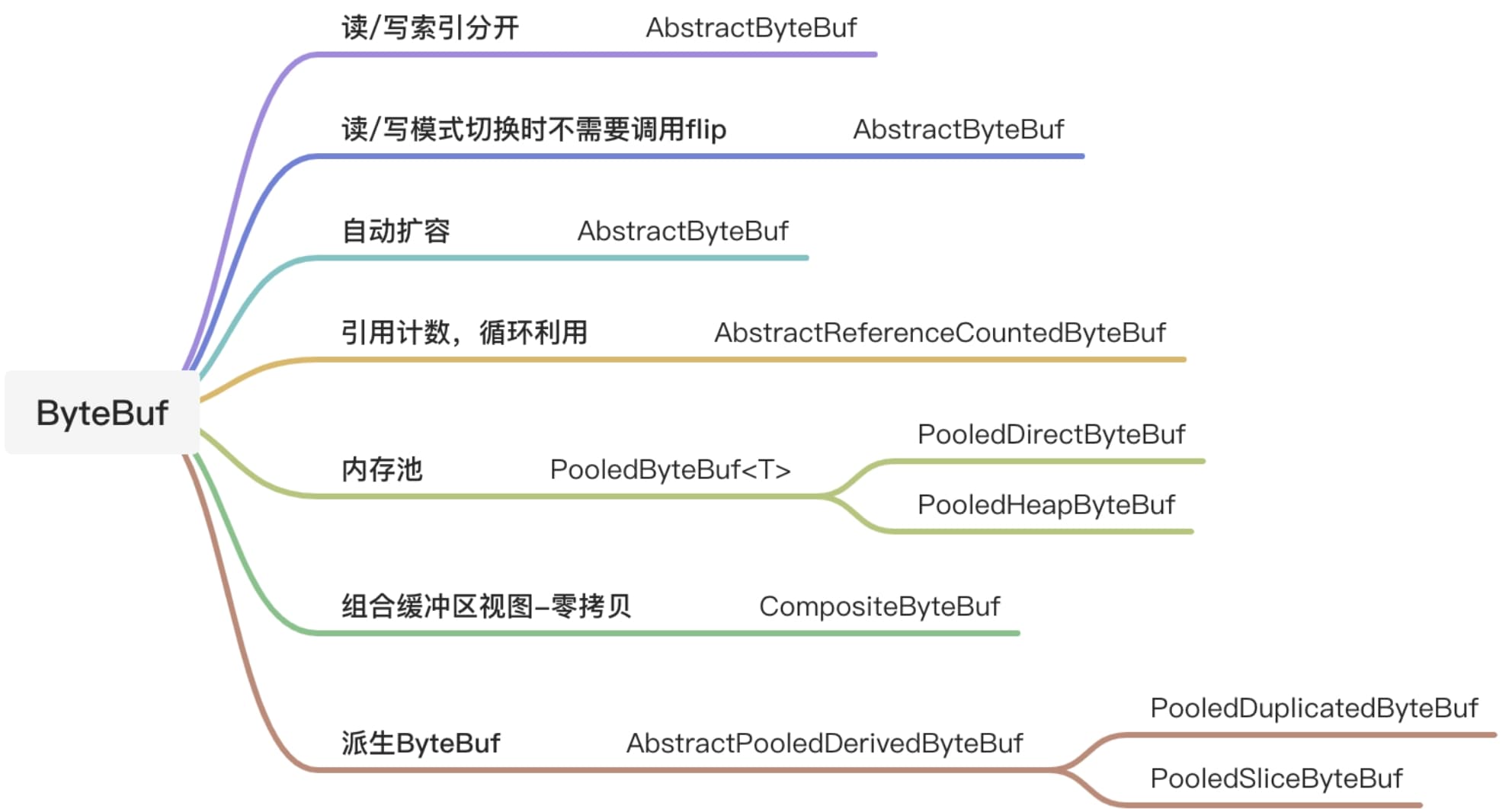
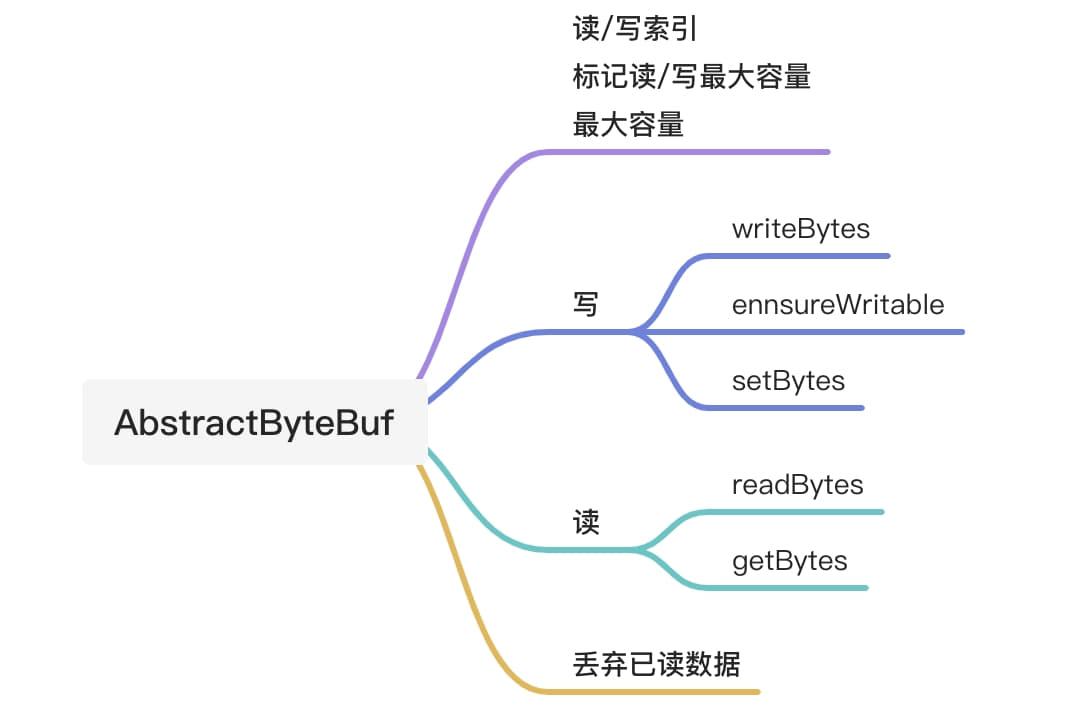
/** * Allocates a new direct byte buffer. * * <p> The new buffer's position will be zero, its limit will be its * capacity, its mark will be undefined, and each of its elements will be * initialized to zero. Whether or not it has a * {@link #hasArray backing array} is unspecified. * * @param capacity * The new buffer's capacity, in bytes * * @return The new byte buffer * * @throws IllegalArgumentException * If the <tt>capacity</tt> is a negative integer */ //java.nio.ByteBuffer#allocateDirect publicstatic ByteBuffer allocateDirect(int capacity){ returnnew DirectByteBuffer(capacity); }
/** * Allocates a new byte buffer. * * <p> The new buffer's position will be zero, its limit will be its * capacity, its mark will be undefined, and each of its elements will be * initialized to zero. It will have a {@link #array backing array}, * and its {@link #arrayOffset array offset} will be zero. * * @param capacity * The new buffer's capacity, in bytes * * @return The new byte buffer * * @throws IllegalArgumentException * If the <tt>capacity</tt> is a negative integer */ //java.nio.ByteBuffer#allocate publicstatic ByteBuffer allocate(int capacity){ if (capacity < 0) thrownew IllegalArgumentException(); returnnew HeapByteBuffer(capacity, capacity); }
/** * Wraps a byte array into a buffer. * * <p> The new buffer will be backed by the given byte array; * that is, modifications to the buffer will cause the array to be modified * and vice versa. The new buffer's capacity will be * <tt>array.length</tt>, its position will be <tt>offset</tt>, its limit * will be <tt>offset + length</tt>, and its mark will be undefined. Its * {@link #array backing array} will be the given array, and * its {@link #arrayOffset array offset} will be zero. </p> * * @param array * The array that will back the new buffer * * @param offset * The offset of the subarray to be used; must be non-negative and * no larger than <tt>array.length</tt>. The new buffer's position * will be set to this value. * * @param length * The length of the subarray to be used; * must be non-negative and no larger than * <tt>array.length - offset</tt>. * The new buffer's limit will be set to <tt>offset + length</tt>. * * @return The new byte buffer * * @throws IndexOutOfBoundsException * If the preconditions on the <tt>offset</tt> and <tt>length</tt> * parameters do not hold */ //java.nio.ByteBuffer#wrap(byte[], int, int) publicstatic ByteBuffer wrap(byte[] array, int offset, int length) { try { returnnew HeapByteBuffer(array, offset, length); } catch (IllegalArgumentException x) { thrownew IndexOutOfBoundsException(); } }
/** * Wraps a byte array into a buffer. * * <p> The new buffer will be backed by the given byte array; * that is, modifications to the buffer will cause the array to be modified * and vice versa. The new buffer's capacity and limit will be * <tt>array.length</tt>, its position will be zero, and its mark will be * undefined. Its {@link #array backing array} will be the * given array, and its {@link #arrayOffset array offset>} will * be zero. </p> * * @param array * The array that will back this buffer * * @return The new byte buffer */ //java.nio.ByteBuffer#wrap(byte[]) publicstatic ByteBuffer wrap(byte[] array){ return wrap(array, 0, array.length); }
wrap(byte[] array, int offset, int length):在上一个方法的基础上可以指定偏移量和长度,这个offset也就是包装后byteBuffer的postion,length是limit-postion的大小,我们可以计算得出limit的位置为length+postion(offset)。
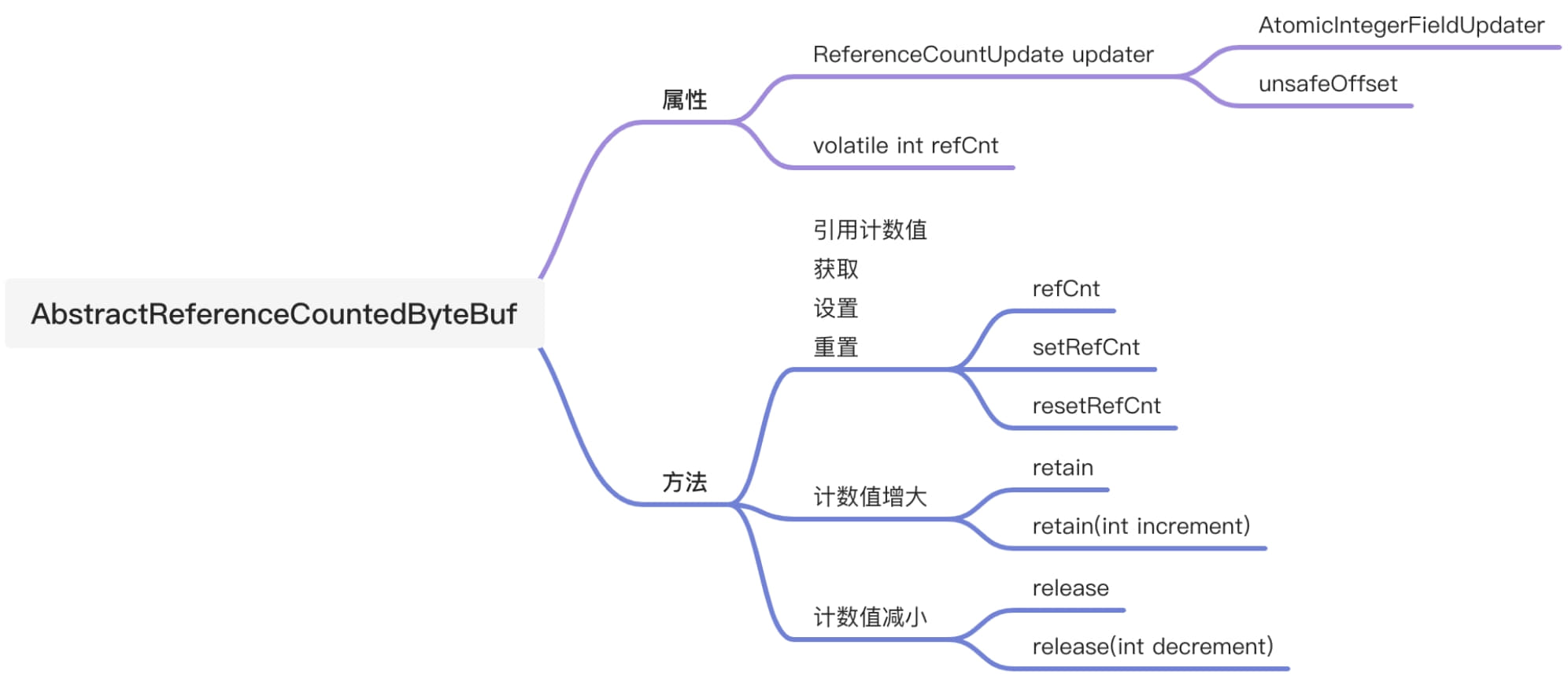
// 引用计数值,初始值为2,与调用refCnt()获取的实际值1有差别。 // Value might not equal "real" reference count, all access should be via the updater @SuppressWarnings({"unused", "FieldMayBeFinal"}) privatevolatileint refCnt = updater.initialValue();
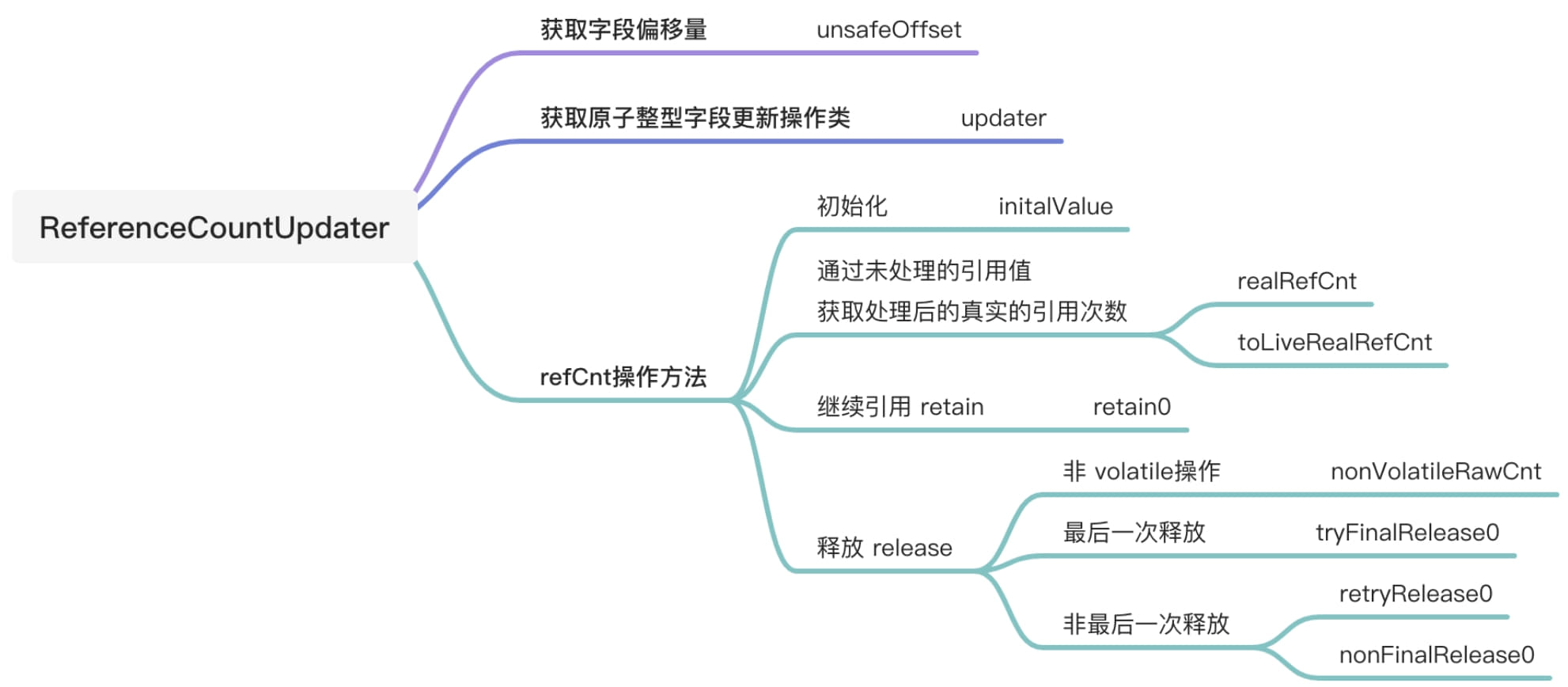
//尝试最终释放,得益于refCnt偶数有效,计数无效,realCnt = rawCnt >>> 1的机制, // 设置refCnt为任意奇数,则表示当前被引用对象无效。 //io.netty.util.internal.ReferenceCountUpdater#tryFinalRelease0 privatebooleantryFinalRelease0(T instance, int expectRawCnt){ return updater().compareAndSet(instance, expectRawCnt, 1); // any odd number will work }
// 非最终释放,如果减少的引用数,少于所有的引用数直接CAS进行操作,如果大于真正的引用数或CAS更新失败, // 则直接调用retryRelease0进行循环更新 //io.netty.util.internal.ReferenceCountUpdater#nonFinalRelease0 privatebooleannonFinalRelease0(T instance, int decrement, int rawCnt, int realCnt){ if (decrement < realCnt // all changes to the raw count are 2x the "real" change - overflow is OK && updater().compareAndSet(instance, rawCnt, rawCnt - (decrement << 1))) { returnfalse; } return retryRelease0(instance, decrement); }
// 尝试进行释放,在这个方法里面是一个死循环,如果减去的引用数decrement是一个非常规的值,方法会直接异常退出, // 如果decremnt的值和所有引用数相等,则会直接尝试最终释放(tryFinalRelease0), // 方法会一直更新直至更新成功。 // 最后调用Thread.yield();让出线程执行权,增加在高并发竞争情况下的吞吐量。 //io.netty.util.internal.ReferenceCountUpdater#retryRelease0 privatebooleanretryRelease0(T instance, int decrement){ for (;;) { int rawCnt = updater().get(instance), realCnt = toLiveRealRefCnt(rawCnt, decrement); if (decrement == realCnt) { if (tryFinalRelease0(instance, rawCnt)) { returntrue; } } elseif (decrement < realCnt) { // all changes to the raw count are 2x the "real" change if (updater().compareAndSet(instance, rawCnt, rawCnt - (decrement << 1))) { returnfalse; } } else { thrownew IllegalReferenceCountException(realCnt, -decrement); } Thread.yield(); // this benefits throughput under high contention } }
//io.netty.util.internal.ReferenceCountUpdater#nonVolatileRawCnt privateintnonVolatileRawCnt(T instance){ // 获取偏移量 // TODO: Once we compile against later versions of Java we can replace the Unsafe usage here by varhandles. finallong offset = unsafeOffset(); // 若偏移量正常,使用Unsafe的普通get // 若偏移量获取异常,则选择Unsafe的volatile get return offset != -1 ? PlatformDependent.getInt(instance, offset) : updater().get(instance); }
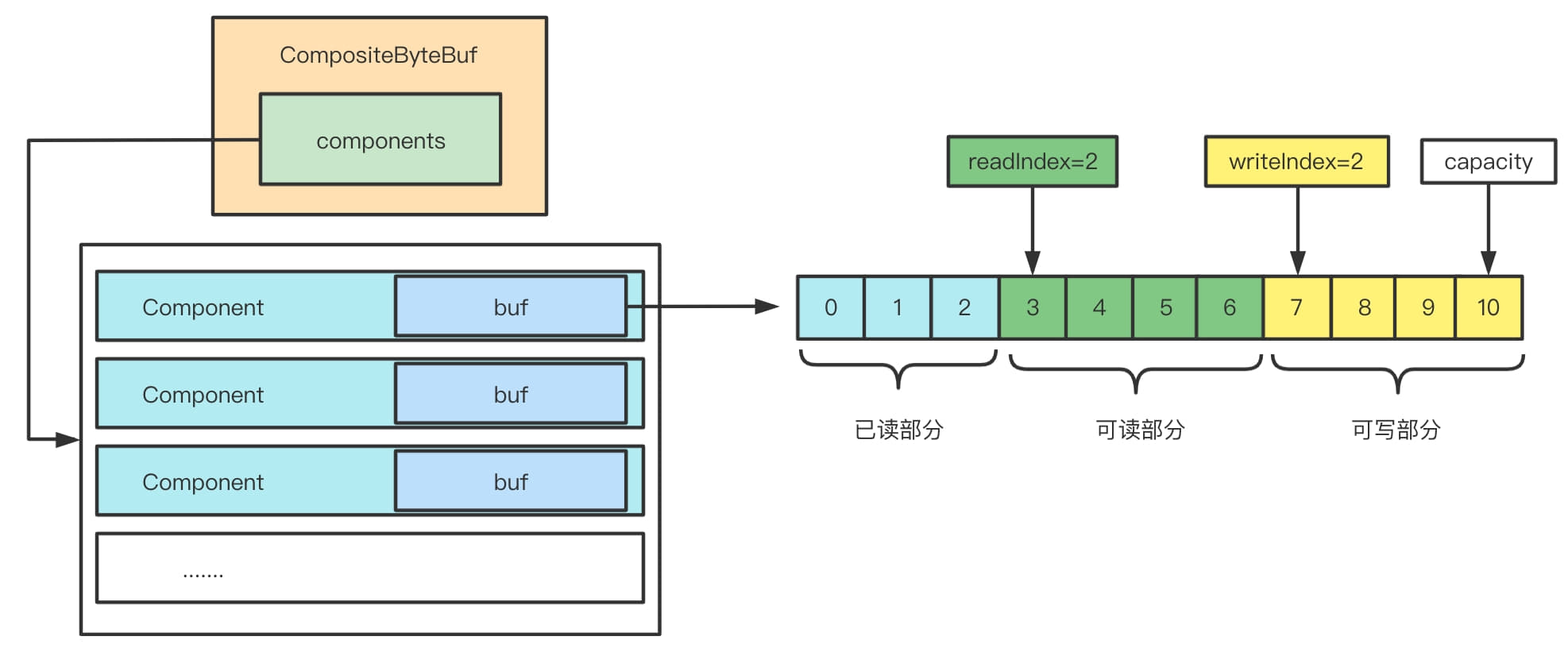
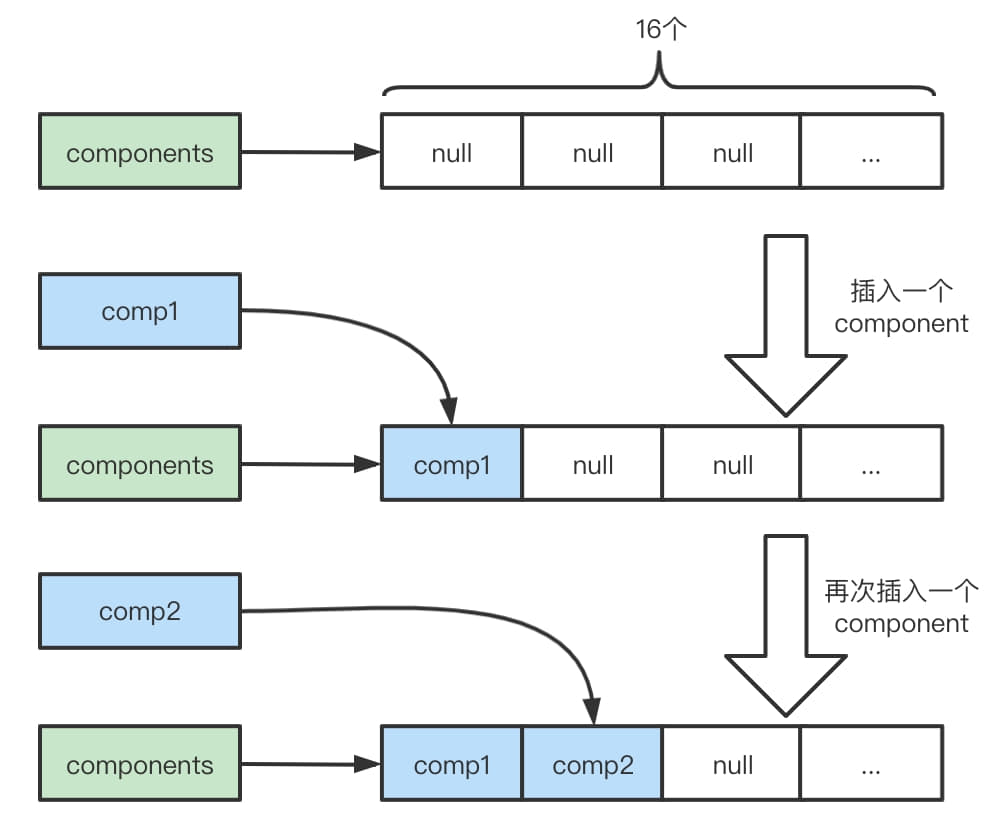
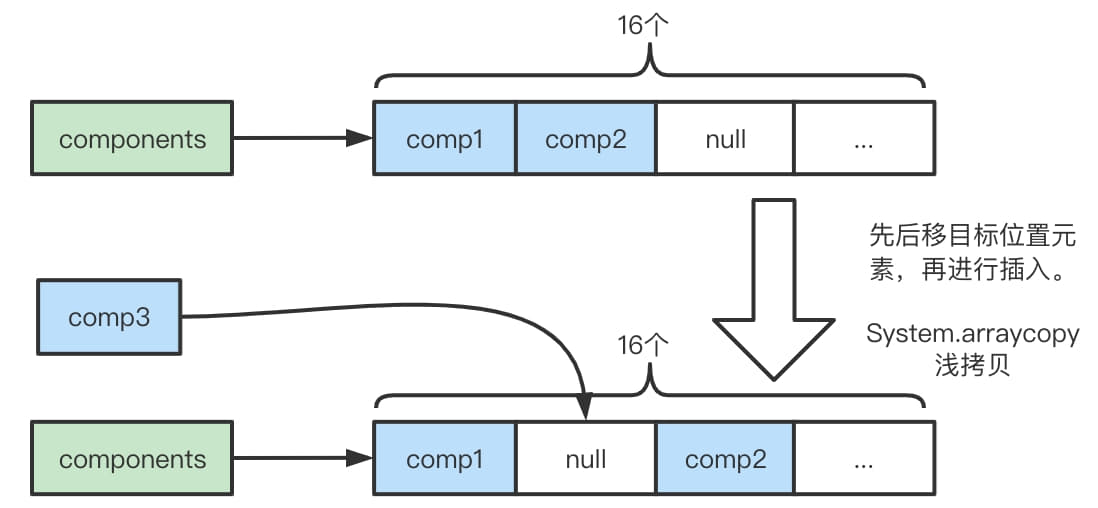
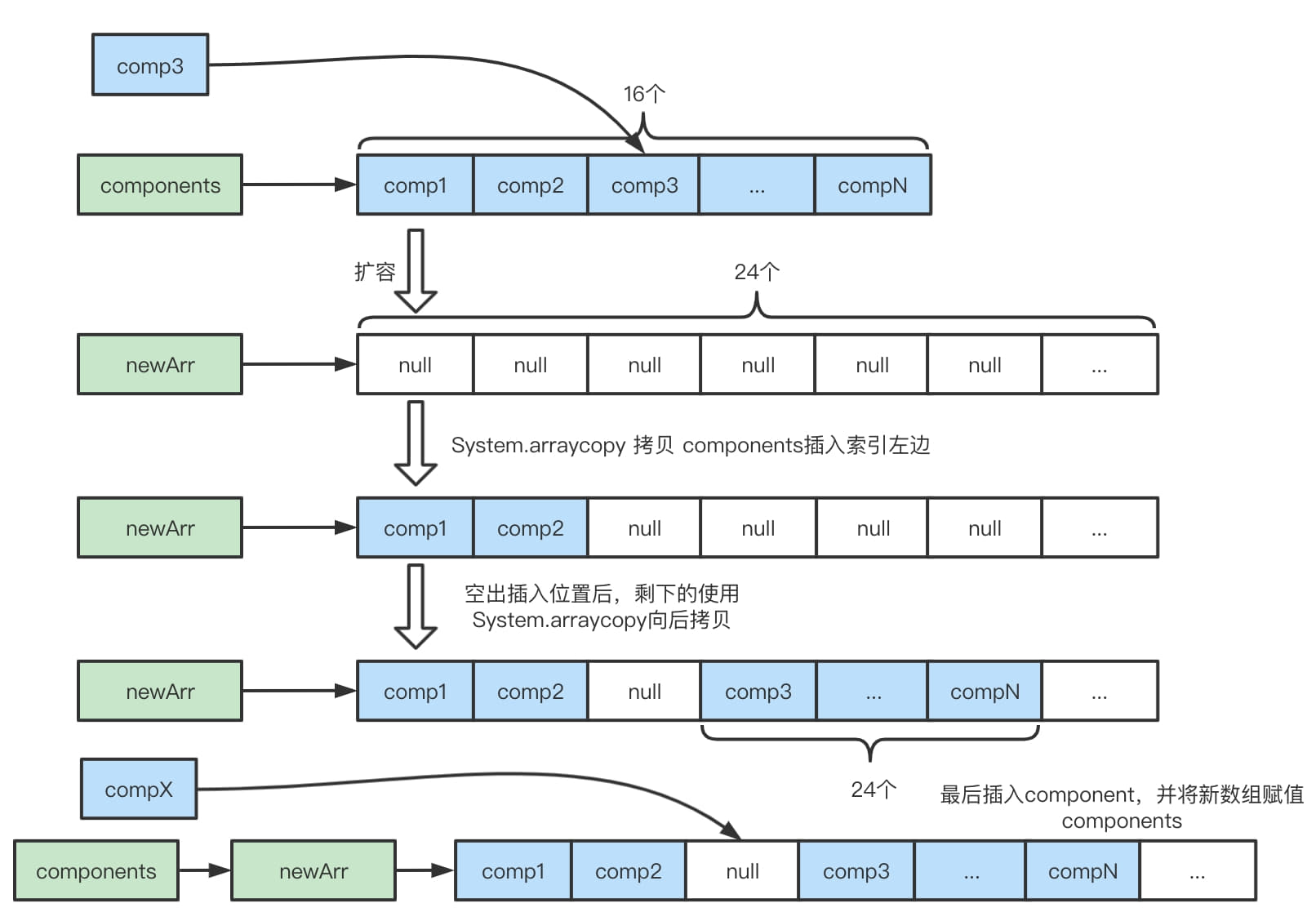
//创建一个新的Component,这里没有必要校验,直接加一个到Component的list中 // No need to consolidate - just add a component to the list. Component c = newComponent(ensureAccessible(buffer), 0); int readableBytes = c.length();
// 校验溢出 // Check if we would overflow. // See https://github.com/netty/netty/issues/10194 checkForOverflow(capacity(), readableBytes);
// We don't need to slice later to expose the internal component if the readable range // is already the entire buffer // 如果可读范围就是容量的话,就可以返回切片,合并后的缓冲去就会有切片 final ByteBuf slice = buf.capacity() == len ? buf : null; // 大端 returnnew Component(buf.order(ByteOrder.BIG_ENDIAN), srcIndex, unwrapped.order(ByteOrder.BIG_ENDIAN), unwrappedIndex, offset, len, slice); }
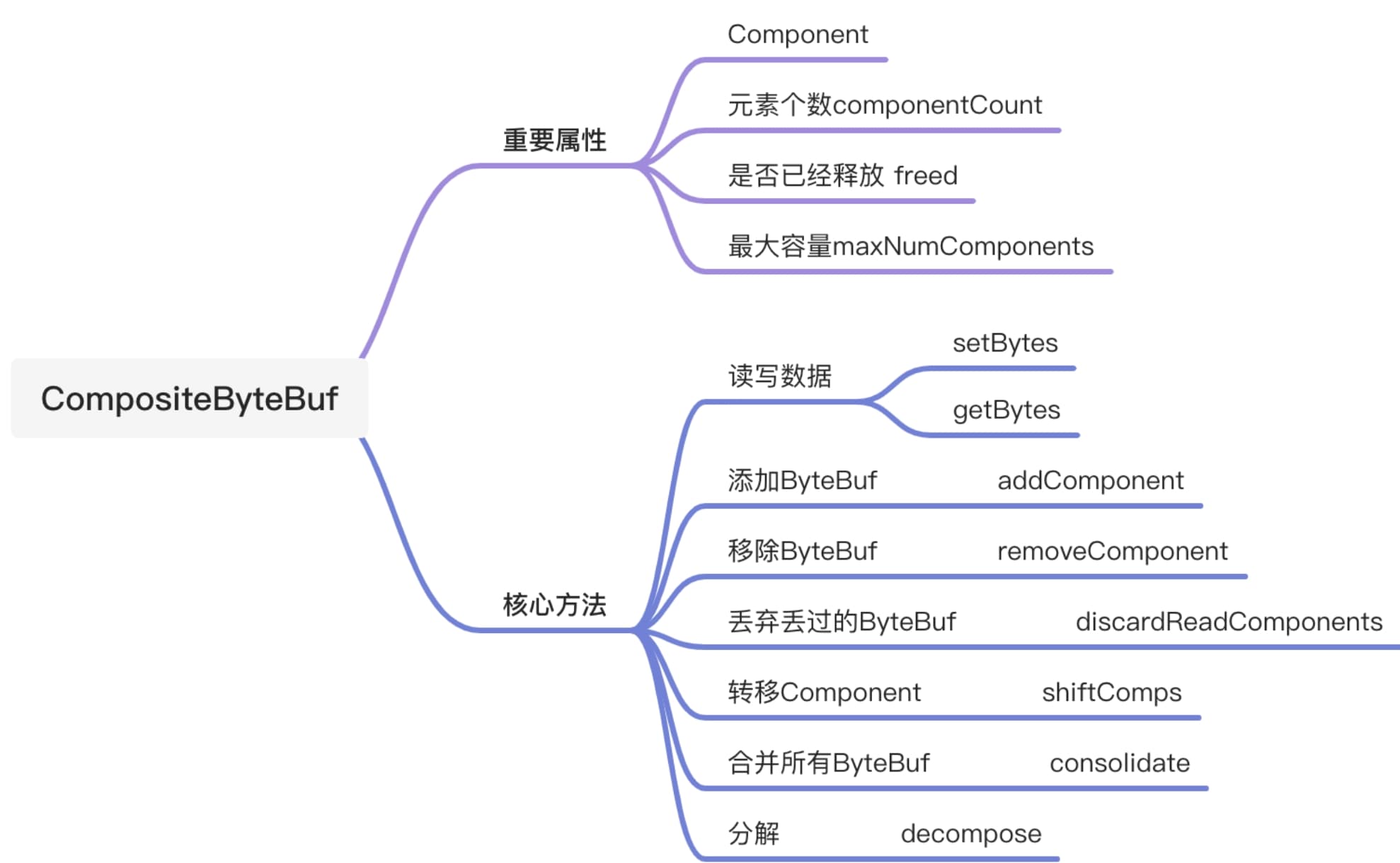
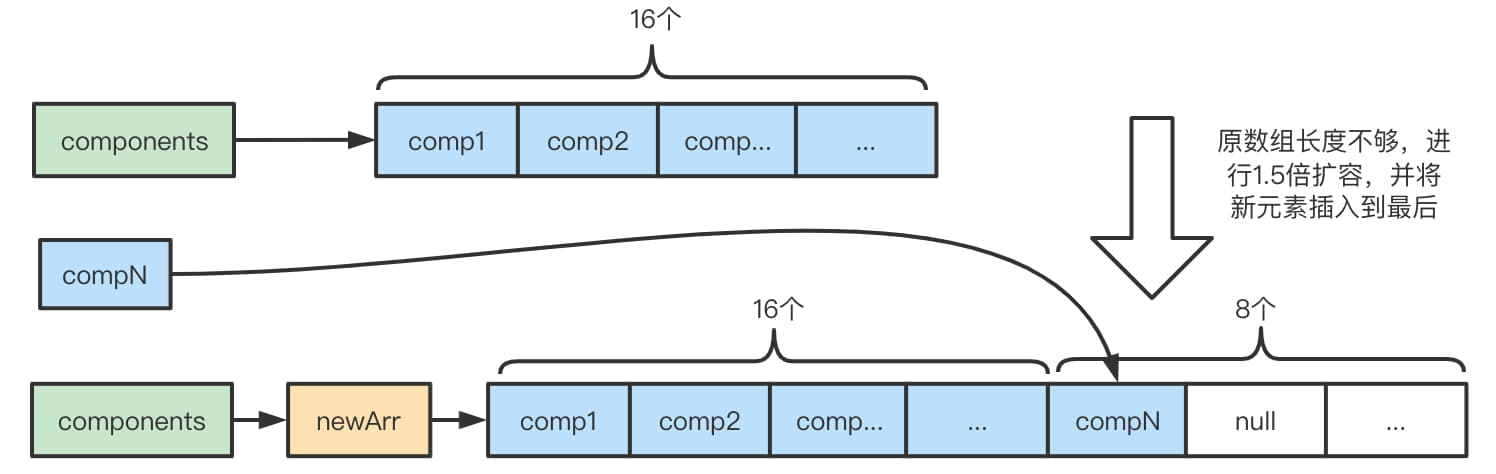
/** * This should only be called as last operation from a method as this may adjust the underlying * array of components and so affect the index etc. */ //io.netty.buffer.CompositeByteBuf#consolidateIfNeeded privatevoidconsolidateIfNeeded(){ // Consolidate if the number of components will exceed the allowed maximum by the current // operation. int size = componentCount; if (size > maxNumComponents) { consolidate0(0, size); 从头开始合并成一个 } }
//io.netty.buffer.CompositeByteBuf#removeComponents public CompositeByteBuf removeComponents(int cIndex, int numComponents){ // 校验要移除位置的索引 checkComponentIndex(cIndex, numComponents);
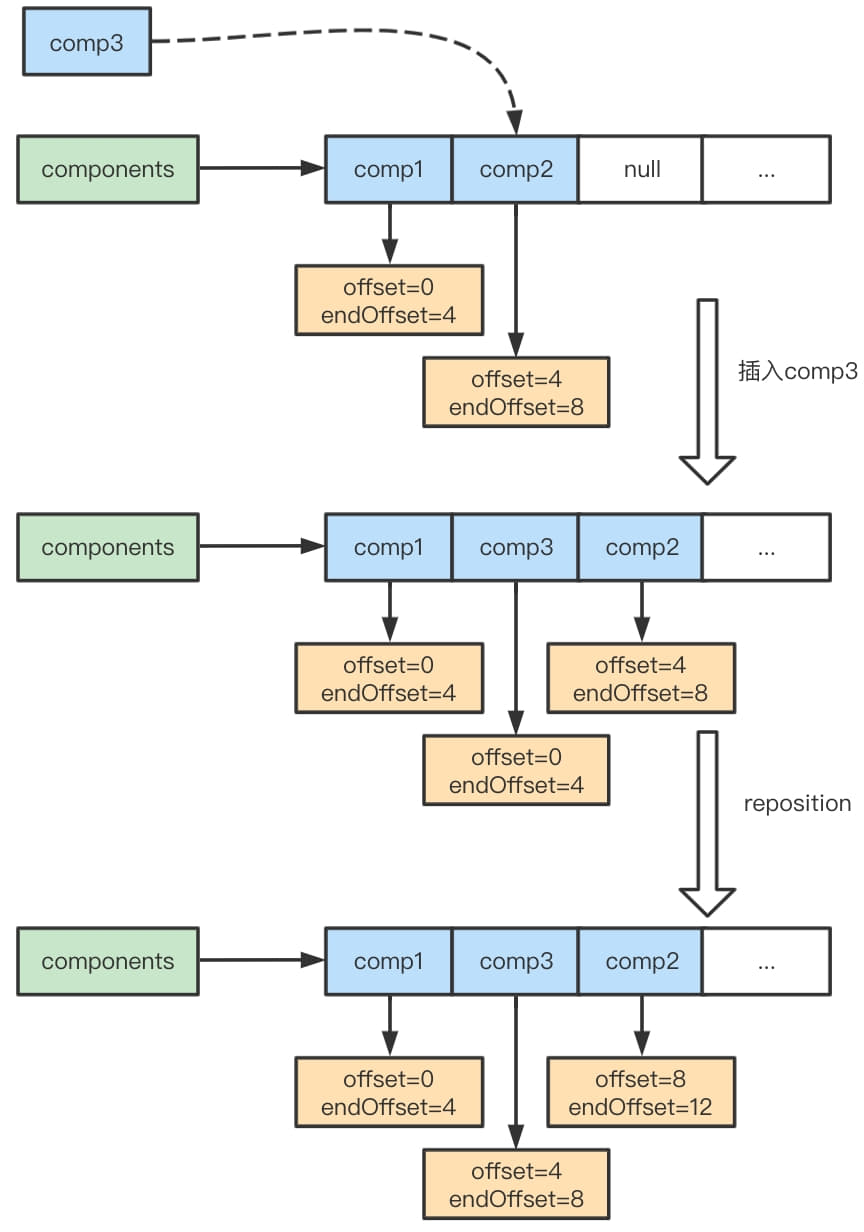
if (numComponents == 0) { returnthis; } //计算移除的范围索引 int endIndex = cIndex + numComponents; boolean needsUpdate = false; for (int i = cIndex; i < endIndex; ++i) { // 循环遍历要移除的component进行释放。 // 如果遍历的component的长度大0,则表明要需要更新数组偏移量。 Component c = components[i]; if (c.length() > 0) { needsUpdate = true; } if (lastAccessed == c) { lastAccessed = null; } c.free(); } // 在数组上移除范围内的component removeCompRange(cIndex, endIndex);
if (needsUpdate) { // Only need to call updateComponentOffsets if the length was > 0 // 更新数组中component的offset。 updateComponentOffsets(cIndex); } returnthis; }